jobconfig.java
package com.mugil.org.config;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.fasterxml.jackson.databind.SerializationFeature;
import com.mugil.org.model.Employee;
import com.mugil.org.model.EmployeeCSV;
import com.mugil.org.model.EmployeeJSON;
import com.mugil.org.model.EmployeeJdbc;
import org.springframework.batch.core.*;
import org.springframework.batch.core.job.builder.JobBuilder;
import org.springframework.batch.core.launch.support.RunIdIncrementer;
import org.springframework.batch.core.repository.JobRepository;
import org.springframework.batch.core.step.builder.StepBuilder;
import org.springframework.batch.item.ItemProcessor;
import org.springframework.batch.item.database.BeanPropertyItemSqlParameterSourceProvider;
import org.springframework.batch.item.database.JdbcBatchItemWriter;
import org.springframework.batch.item.database.JdbcCursorItemReader;
import org.springframework.batch.item.database.builder.JdbcBatchItemWriterBuilder;
import org.springframework.batch.item.database.builder.JdbcCursorItemReaderBuilder;
import org.springframework.batch.item.file.FlatFileItemReader;
import org.springframework.batch.item.file.FlatFileItemWriter;
import org.springframework.batch.item.file.LineMapper;
import org.springframework.batch.item.file.builder.FlatFileItemReaderBuilder;
import org.springframework.batch.item.file.builder.FlatFileItemWriterBuilder;
import org.springframework.batch.item.file.mapping.BeanWrapperFieldSetMapper;
import org.springframework.batch.item.file.mapping.DefaultLineMapper;
import org.springframework.batch.item.file.transform.BeanWrapperFieldExtractor;
import org.springframework.batch.item.file.transform.DelimitedLineAggregator;
import org.springframework.batch.item.file.transform.DelimitedLineTokenizer;
import org.springframework.batch.item.file.transform.LineAggregator;
import org.springframework.batch.item.json.JacksonJsonObjectReader;
import org.springframework.batch.item.json.JsonItemReader;
import org.springframework.batch.item.json.builder.JsonItemReaderBuilder;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.FileSystemResource;
import org.springframework.jdbc.core.BeanPropertyRowMapper;
import org.springframework.transaction.PlatformTransactionManager;
import javax.sql.DataSource;
import java.util.Date;
@Configuration
public class JobConfig {
@Autowired
ItemProcessor simpleJobProcessor;
@Autowired
DataSource dataSource;
@Bean
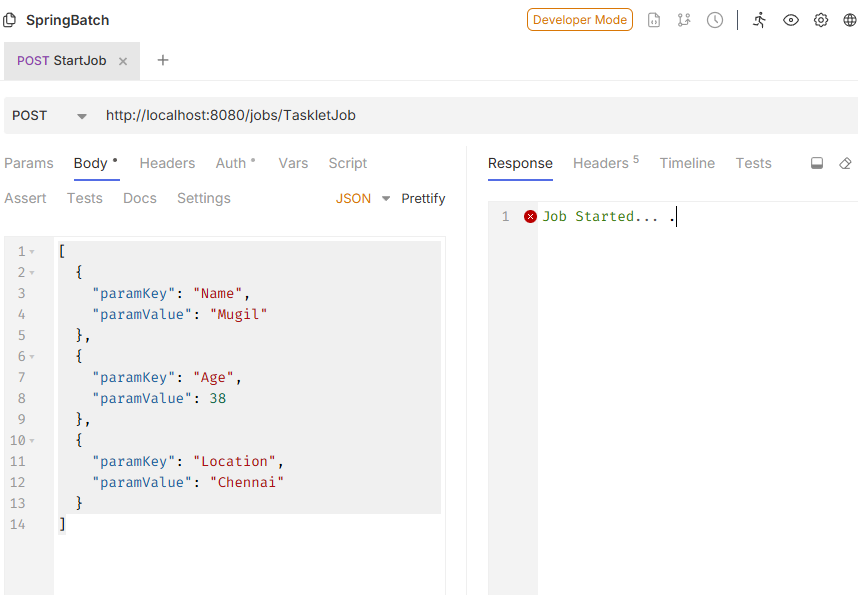
public Job job(JobRepository jobRepository, PlatformTransactionManager transactionManager) {
return new JobBuilder("job", jobRepository)
.incrementer(new RunIdIncrementer())
.start(simpleChunkStep(jobRepository, transactionManager))
.build();
}
@Bean
public Step simpleChunkStep(JobRepository jobRepository, PlatformTransactionManager transactionManager) {
StepBuilder stepBuilderOne = new StepBuilder("Chunk Oriented Step", jobRepository);
return stepBuilderOne
.chunk(3, transactionManager)
.reader(flatFileItemReader())
.processor(simpleJobProcessor)
.writer(jdbcWriter())
.build();
}
@Bean
public JsonItemReader<EmployeeJSON> jsonFileReader() {
return new JsonItemReaderBuilder<EmployeeJSON>()
.name("employeeJSONReader")
.jsonObjectReader(new JacksonJsonObjectReader<>(EmployeeJSON.class))
.currentItemCount(1) //Skip the first item
.maxItemCount(3) //Limit reading to a maximum of 3 items from the file
.resource(new FileSystemResource("EmployeeList.json"))
.build();
}
@Bean
public FlatFileItemWriter<EmployeeJSON> jsonFileWriter() {
ObjectMapper objectMapper = new ObjectMapper();
objectMapper.enable(SerializationFeature.INDENT_OUTPUT); // Optional: pretty print
LineAggregator<EmployeeJSON> jsonLineAggregator = item -> {
try {
return objectMapper.writeValueAsString(item);
} catch (JsonProcessingException e) {
throw new RuntimeException("Error converting Employee to JSON", e);
}
};
return new FlatFileItemWriterBuilder<EmployeeJSON>()
.name("employeeJsonTxtWriter")
.resource(new FileSystemResource("OutputFiles/employees.json"))
.lineAggregator(jsonLineAggregator)
.build();
}
@Bean
public FlatFileItemReader<Employee> flatFileItemReader() {
FlatFileItemReader<Employee> flatFileItemReader = new FlatFileItemReader<>();
flatFileItemReader.setResource(new FileSystemResource("InputFiles/EmployeeList.txt"));
flatFileItemReader.setLineMapper(lineMapper());
return flatFileItemReader;
}
@Bean
public FlatFileItemWriter<Employee> flatFileWriter() {
BeanWrapperFieldExtractor<Employee> fieldExtractor = new BeanWrapperFieldExtractor<>();
fieldExtractor.setNames(new String[] {"id", "name", "location", "age"});
FileSystemResource fileSystemResource = new FileSystemResource("OutputFiles/employeeList.txt");
DelimitedLineAggregator<Employee> lineAggregator = new DelimitedLineAggregator<>();
lineAggregator.setDelimiter(",");
lineAggregator.setFieldExtractor(fieldExtractor);
return new FlatFileItemWriterBuilder<Employee>()
.name("flatFileItemWriter") //helps to uniquely recognize a job incase of need for retry
.resource(fileSystemResource)
.lineAggregator(lineAggregator)
.footerCallback(writer -> writer.write("Created @ " + new Date()))
.build();
}
@Bean
public FlatFileItemReader<EmployeeCSV> csvFileReader() {
return new FlatFileItemReaderBuilder<EmployeeCSV>()
.name("employeeCSVReader")
.resource(new FileSystemResource("EmployeeList.csv"))
.linesToSkip(1)
.delimited()
.names("ID", "Name", "Location", "Age")
.targetType(EmployeeCSV.class)
.build();
}
@Bean
public FlatFileItemWriter<Employee> csvFileWriter() {
BeanWrapperFieldExtractor<Employee> fieldExtractor = new BeanWrapperFieldExtractor<>();
fieldExtractor.setNames(new String[] {"id", "name", "location", "age"});
FileSystemResource fileSystemResource = new FileSystemResource("OutputFiles/EmployeeList.csv");
DelimitedLineAggregator<Employee> lineAggregator = new DelimitedLineAggregator<>();
lineAggregator.setDelimiter(",");
lineAggregator.setFieldExtractor(fieldExtractor);
return new FlatFileItemWriterBuilder<Employee>()
.name("csvItemWriter")
.resource(fileSystemResource)
.lineAggregator(lineAggregator)
.headerCallback(writer -> writer.write("ID,Name,Age,Location"))
.build();
}
@Bean
public JdbcCursorItemReader<EmployeeJdbc> jdbcReader() {
return new JdbcCursorItemReaderBuilder<EmployeeJdbc>()
.name("employeeJDBCReader")
.dataSource(dataSource)
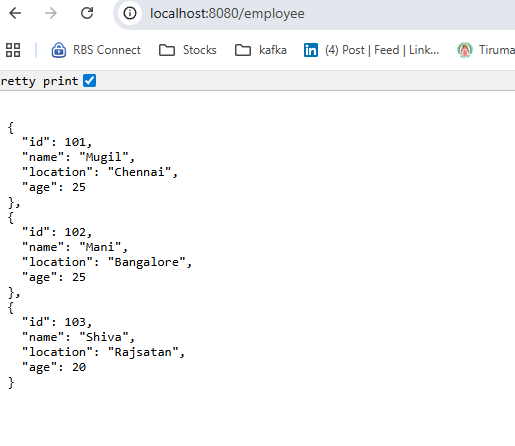
.sql("SELECT id, name, age, location FROM public.tblemployee")
.rowMapper(new BeanPropertyRowMapper<>(EmployeeJdbc.class))
.build();
}
@Bean
public JdbcBatchItemWriter<Employee> jdbcWriter() {
return new JdbcBatchItemWriterBuilder<Employee>()
.itemSqlParameterSourceProvider(new BeanPropertyItemSqlParameterSourceProvider<>())
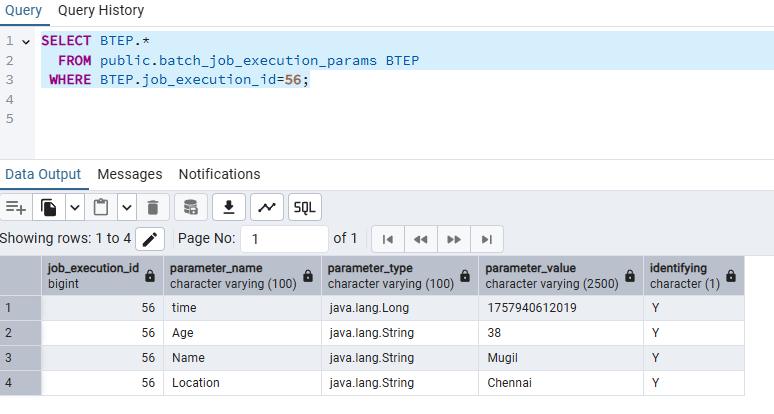
.sql("INSERT INTO tblemployee (id, name, location, age) VALUES (:id, :name, :location, :age)")
.dataSource(dataSource)
.build();
}
@Bean
public LineMapper<Employee> lineMapper() {
DefaultLineMapper<Employee> lineMapper = new DefaultLineMapper<>();
// Step 1: Tokenize the line
DelimitedLineTokenizer tokenizer = new DelimitedLineTokenizer();
tokenizer.setDelimiter(","); // Default is comma
tokenizer.setNames("ID", "Name", "Location", "Age"); // Must match CSV header
// Step 2: Map tokens to bean properties
BeanWrapperFieldSetMapper<Employee> fieldSetMapper = new BeanWrapperFieldSetMapper<>();
fieldSetMapper.setTargetType(Employee.class);
fieldSetMapper.setStrict(true); // Optional: disables fuzzy matching
// Step 3: Combine tokenizer and mapper
lineMapper.setLineTokenizer(tokenizer);
lineMapper.setFieldSetMapper(fieldSetMapper);
return lineMapper;
}
}
SimpleJobProcessor.java
import com.mugil.org.model.Employee;
import org.springframework.batch.item.ItemProcessor;
import org.springframework.stereotype.Component;
@Component
public class SimpleJobProcessor implements ItemProcessor<Employee, Employee> {
@Override
public Employee process(Employee item) throws Exception {
System.out.println("Inside Job Processor");
String employeeDetails = "The Employee Name is " + item.getName() + ", his Age is " + item.getAge() + " and location is " + item.getLocation();
System.out.println(employeeDetails);
Employee objEmp = new Employee(item.getId(), item.getName(), item.getLocation(), item.getAge());
return objEmp;
}
}