Getting Count in JPA
JPA COUNT returns a Long
When extracting the count from the table JPA returns long based on the type of query used.
JPQL
Query query = em.createQuery("SELECT COUNT(p) FROM PersonEntity p " );
query.getSingleResult().getClass().getCanonicalName() --> java.lang.Long
Native Query
Query query = em.createNativeQuery("SELECT COUNT(*) FROM PERSON");
query.getSingleResult().getClass().getCanonicalName() --> java.math.BigInteger
If it is Native Query big Integer is returned or if it is JPQL then Long is returned.
So before assigning to Integer the value should be typecasted.
int count = ((Number)arrCount.get[0]).intValue(); System.out.println(count);
Needs to be Removed
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:context="http://www.springframework.org/schema/context"
xmlns:tx="http://www.springframework.org/schema/tx" xmlns:jpa="http://www.springframework.org/schema/data/jpa"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-3.0.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/tx
http://www.springframework.org/schema/data/jpa http://www.springframework.org/schema/data/jpa/spring-jpa.xsd">
<context:annotation-config />
<context:component-scan base-package="" />
<tx:annotation-driven transaction-manager="transactionManager"/>
<bean id="transactionManager" class="org.springframework.orm.jpa.JpaTransactionManager">
<property name="entityManagerFactory" ref="entityManagerFactory" />
</bean>
<!-- Configure the entity manager factory bean -->
<bean id="entityManagerFactory"
class="org.springframework.orm.jpa.LocalContainerEntityManagerFactoryBean">
<property name="dataSource" ref="dataSource" />
<property name="jpaVendorAdapter" ref="hibernateJpaVendorAdapter" />
<!-- Set JPA properties -->
<property name="jpaProperties">
<props>
<prop key="hibernate.dialect">org.hibernate.dialect.Oracle10g</prop>
</props>
</property>
<!-- Set base package of your entities -->
<property name="packagesToScan" value="com.mugil.org.model" />
</bean>
<beans:bean id="dbDataSource" class="org.springframework.jndi.JndiObjectFactoryBean" scope="singleton" lazy-init="true">
<beans:property name="jndiName" value="java:jboss/datasources/TurboDS"/>
</beans:bean>
</beans>
JPA Interview Questions
What is PersistenceContext
A persistence context handles a set of entities which hold data to be persisted in some persistence store (e.g. a database).Entities are managed by javax.persistence.EntityManager instance using persistence context.Each EntityManager instance is associated with a persistence context. Within the persistence context, the entity instances and their lifecycle are managed.Persistence context defines a scope under which particular entity instances are created, persisted, and removed.
A persistence context is like a cache which contains a set of persistent entities , So once the transaction is finished, all persistent objects are detached from the EntityManager’s persistence context and are no longer managed
A Cache is a copy of data, copy meaning pulled from but living outside the database.Flushing a Cache is the act of putting modified data back into the database.
A PersistenceContext is essentially a Cache(copy of data from database outside database). It also tends to have it’s own non-shared database connection.An EntityManager represents a PersistenceContext (and therefore a Cache).An EntityManagerFactory creates an EntityManager(and therefore a PersistenceContext/Cache)
What is the difference between LocalContainerEntityManagerFactoryBean and LocalEntityManagerFactoryBean?
JPA specification defines two types of entity managers.
| LocalEntityManagerFactoryBean | LocalContainerEntityManagerFactoryBean |
|---|---|
| Entity Managers are created and managed by merely the application(“opening , closing and involving entity manager in transactions”) | Entity Managers are created and managed by merely the J2EE container |
| creates a JPA EntityManagerFactory according to JPA’s standard standalone bootstrap contract | creates a JPA EntityManagerFactory according to JPA’s standard container bootstrap contract. |
| Application-managed EntityManagers are created by an EntityManagerFactory obtained by calling the createEntityManagerFactory() | container-managed EntityManagerFactorys are obtained through PersistenceProvider’s createContainerEntityManagerfactory() |
| LocalEntityManagerFactoryBean produces an application-managed Entity- ManagerFactory. | LocalContainerEntityManagerFactoryBean produces a container-managed EntityManagerFactory |
The only real difference between application-managed and container-managed entity manager factories, as far as Spring is concerned, is how each is configured in the Spring application context.
When to use JPA getSingleResult()
getSingleResult() is used in situations like: “I am totally sure that this record exists. I don’t want to test for null every time I use this method because I am sure that it will not return it. Otherwise it causes alot of boilerplate and defensive programming. And if the record really does not exist (as opposite to what we’ve assumed), it is much better to have NoResultException compared to NullPointerException. If the record is not found it throws NoResultException
When the JPA Entities will become detached
- When the transaction (in transaction-scoped persistence context) commits, entities managed by the persistence context become detached.
- If an application-managed persistence context is closed, all managed entities become detached.
- Using clear method
- using detach method
- rollback
- In extended persistence context when a stateful bean is removed, all managed entities become detached.
What is JPADialect
Dialect is “the variant of a language”.Speaking about Hibernate in context hibernate works with different databases.hibernate has to use database specific SQL. Hibernate uses “dialect” configuration to know which database you are using so that it can switch to the database specific SQL generator code wherever/whenever necessary
<bean id="jpaDialect" class="org.springframework.orm.jpa.vendor.jpaDialect"/>
Now in the above statement I have specified that the jpaDialect I am going to use is of Hibernate Variant of implementation for JPA and Spring needs to take this into consideration
while creating entityManagerFactory.
The way it is referred is as follows
<bean id="transactionManager" class="org.springframework.orm.jpa.JpaTransactionManager">
<property name="entityManagerFactory" ref="entityManagerFactory"/>
<property name="jpaDialect" ref="jpaDialect"/>
</bean>
Why we need JPAVendorAdapter
EntityManagerFactory manages the lifecycle of the entities.Persistence Provider is the one which specifies the details about the database and connection details of the underlying database either by persistence-context.xml or by injecting instances of EntityManager using @PersistenceContext annotation. JPAVendorAdapter helps to define the persistence context which is likely to be used.
Persistence-context.xml
<persistence-unit name="MyPersistenceUnit" transaction-type="RESOURCE_LOCAL">
<provider>org.hibernate.ejb.HibernatePersistence</provider>
<non-jta-data-source>java:comp/env/jdbc/ooes_master</non-jta-data-source>
<properties>
<property name="hibernate.dialect" value="org.hibernate.dialect.MySQL5Dialect"/>
<property name="hibernate.show_sql" value="true"/>
<property name="hibernate.hbm2ddl.auto" value="update"/>
<property name="hibernate.cache.region.factory_class" value="net.sf.ehcache.hibernate.SingletonEhCacheRegionFactory"/>
<property name="hibernate.cache.use_second_level_cache" value="true"/>
<property name="hibernate.cache.use_query_cache" value="true"/>
</properties>
</persistence-unit>
If we want to inject instances of EntityManager using @PersistenceContext annotation, we have to enable annotation bean processor in Spring configuration
<bean class="org.springframework.orm.jpa.support.PersistenceAnnotationBeanPostProcessor" />
Usually this line is optional because a default PersistenceAnnotationBeanPostProcessor will be registered by the
getSingleResult() return detached or Managed Object
objects returned from .getResultList() are managed.When you made changes on the managed objects, you do not worry about merging as those changes will be picked up by the EntityManager automatically.The managed objects will become detached when the EntityManager that is used to load that object is close(), clear() or detach(). Detached objects are not manged anymore and you should do merging to let the EntityManager pick up the changes.
JBoss Tweaks
Jboss Timeout during deployment
Add the below entries in Standalone xml file
Standalone.xml
<subsystem xmlns="urn:jboss:domain:deployment-scanner:1.0">
<deployment-scanner scan-interval="5000" relative-to="jboss.server.base.dir" path="deployments" deployment-timeout="1000" />
</subsystem>
deployment-timeout=”1000″ is set to 1000 seconds.
Suppressing Errors in JBOSS using ID
JBAS011006: Not installing optional component org.springframework.web.context.request.async.StandardServletAsyncWebRequest due to exception: org.jboss.as.server.deployment.DeploymentUnitProcessingException
Standalone.xml
<subsystem xmlns="urn:jboss:domain:logging:1.1">
<console-handler name="CONSOLE">
<filter>
<not>
<match pattern="JBAS011054|JBAS011006"/>
</not>
</filter>
</console-handler>
</subsystem>
JBOSS clearing Temp Files
Parameters to be set when server VM start
-Djboss.vfs.cache=org.jboss.virtual.plugins.cache.IterableTimedVFSCache -Djboss.vfs.cache.TimedPolicyCaching.lifetime=1440
JBOSS Config parameters
jboss.home.dir - The base directory of the jboss distribution - default: $JBOSS_HOME jboss.home.url - The base url of the jboss distribution - default $JBOSS_HOME jboss.lib.url - The url where the kernel jars exist - default: $jboss.home.url/lib jboss.patch.url - A directory where patch jars exist - default: none jboss.server.name - The configuration name of the server - default: default jboss.server.base.dir - The directory where server configurations exist - default: $jboss.home.dir/server jboss.server.base.url - The url where server configurations exist - default: $jboss.home.url/server jboss.server.home.dir - The directory for the current configuration - default: $jboss.server.base.dir/$jboss.server.name jboss.server.home.url - The url for the current configuration - default: $jboss.server.base.url/$jboss.server.name jboss.server.temp.dir - The directory for temporary files - default: $jboss.server.home.dir/tmp jboss.server.data.dir - The directory for data files - default: $jboss.server.home.dir/data jboss.server.config.url - The url for configuration files - default: $jboss.server.home.url/conf jboss.server.lib.url - The url for static jar files - default: $jboss.server.home.url/lib jboss.server.log.dir - The directory where the server logs are written - default: $jboss.server.home.dir/log
For Example, if you want JBoss to write the server log file to “C:/Logs/”, then what you should do is to set a system property as this
-Djboss.server.log.dir=C:/Logs/
SLF4J Errors
java.lang.NoSuchMethodError: org.slf4j.helpers.MessageFormatter.format(Ljava/lang/String;Ljava/lang/Object;)
Solution
The Reason for the above error is version mis-match between the various SLF4J API. (e.g. 1.6.x is not backwards compatible with 1.5.x). Make sure you have no duplicate jars in your classpath. If exists exclude them and add these dependencies to your classpath
pom.xml
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.6.2</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.6.2</version>
</dependency>
In the above code the Version of API and Implementation should be same(i.e. 1.6.2)
What is SLF4J
SLF4J is basically an abstraction layer. It is not a logging implementation. It means that if you’re writing a library and you use SLF4J, you can give that library to someone else to use and they can choose which logging implementation to use with SLF4J e.g. log4j or the Java logging API. It helps prevent projects from being dependent on lots of logging APIs just because they use libraries that are dependent on them.
Hibernate Errors
org.hibernate.AnnotationException: Use of @OneToMany or @ManyToMany targeting an unmapped class
Sol
- @Entity Should be added in the Model class
- If you have missed to add the Model class in the xml file
- Make sure the annotation is javax.persistence.Entity, and not org.hibernate.annotations.Entity. The former makes the entity detectable.
————————————————————————————————————————————————————-
javax.naming.NoInitialContextException: Need to specify class name in environment or system property
Sol
“I want to find the telephone number for John Smith, but I have no phonebook to look in”.This exception is thrown when no initial context implementation can be created.JNDI (javax.naming) is all about looking up objects or resources from some directory or provider. To look something up, you need somewhere to look (this is the InitialContext).
————————————————————————————————————————————————————-
hibernate exception: org.hibernate.AnnotationException: No identifier specified for entity
Sol
- You are missing a field annotated with @Id. Each @Entity needs an @Id – this is the primary key in the database.
- If you don’t want your entity to be persisted in a separate table, but rather be a part of other entities, you can use @Embeddable instead of @Entity.
- If you want simply a data transfer object to hold some data from the hibernate entity, use no annotations on it whatsoever – leave it a simple pojo.
————————————————————————————————————————————————————-
org.hibernate.hql.internal.ast.QuerySyntaxException: table is not mapped
Sol
In the HQL , you should use the java class name and property name of the mapped @Entity instead of the actual table name and column name
For example if your bean class name is UserDetails then the Hibernate code should be as below.Not Tbl_UserDetails instead of UserDetails
Query query = entityManager. createQuery("Select UserName from UserDetails");
The problem can also be because of wrong import
import javax.persistence.Entity;
instead of
import org.hibernate.annotations.Entity;
————————————————————————————————————————————————————-
Resolution will not be reattempted until the update interval of MyRepo has elapsed
Failure to find org.jfrog.maven.annomojo:maven-plugin-anno:jar:1.4.0 in http://myrepo:80/artifactory/repo was cached in the local repository, resolution will not be reattempted until the update interval of MyRepo has elapsed or updates are forced -> [Help 1]
The above statement tells that the artifact is cached in local repository.Now the artifact is not going to get downloaded unless it is
- It is forced to update from client Side
- Forcing from server side the expiration time
From Client Side 3 Solutions
- Using Maven Update to force update Snapshots(Mostly doesn’t work)
- Deleting the failed directory of Snapshot and forcing it to download
- By setting the Time interval for looking for Snapshot
c:\Users\mugilvannan\maven\conf\settings.xml<profile> <id>nexus</id> <!--Enable snapshots for the built in central repo to direct --> <!--all requests to nexus via the mirror --> <repositories> <repository> <id>central</id> <url>http://central</url> <releases><enabled>true</enabled><updatePolicy>always</updatePolicy></releases> <snapshots><enabled>true</enabled><updatePolicy>always</updatePolicy></snapshots> </repository> </repositories> <pluginRepositories> <pluginRepository> <id>central</id> <url>http://central</url> <releases><enabled>true</enabled><updatePolicy>always</updatePolicy></releases> <snapshots><enabled>true</enabled><updatePolicy>always</updatePolicy></snapshots> </pluginRepository> </pluginRepositories> </profile>
AnnotationSessionFactoryBean Spring
- AnnotationSessionFactoryBean is used to create session factory if hibernate pojo are annotated
- AnnotationSessionFactoryBean is a factory that produces SessionFactory automatically.This is used when you create a sessionFactory object of Hibernate from Spring
<bean id="sessionFactory" class="org.springframework.orm.hibernate3. annotation.AnnotationSessionFactoryBean"> <property name="dataSource" ref="dataSource"/> <property name="annotatedClasses"> <list> <value>test.package.Foo</value> <value>test.package.Bar</value> </list> </property> </bean> - This session factory is assigned to all dao beans and hibernate template to do database transaction.
<bean id="hibernateTemplate" class="org.springframework.orm.hibernate3. HibernateTemplate"> <property name="sessionFactory"> <ref bean="sessionFactory" /> </property> </bean> <bean id="pageDao" class="com.concretepage.dao.PageDaoImpl"> <property name="hibernateTemplate"> <ref bean="hibernateTemplate" /> </property> </bean>
Visitor Pattern Example
Lets take the below scenario where there are Different segment of customers whose discount rates is going to vary based on the segment type and the Store they are visiting
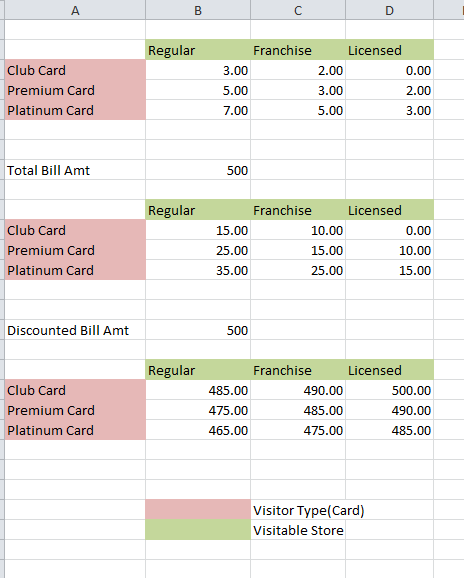
Now the Customer may hold Platinum,Premium or Club Card which avails them some discount on the total bill amount.
Again this discount vary based on the store from which the purchase is made Regular, Franchise, Licensed Store
Visitor.java
package com.mugil.visitor;
public interface Visitor {
public double getDiscount(FranchiseStore objFranchiseStore);
public double getDiscount(RegularStore objRegularStore);
public double getDiscount(LicensedStore objLicensedStore);
}
Visitable.java
package com.mugil.visitor;
public interface Visitable {
public double acceptDiscount(Visitor objVisitior);
}
FranchiseStore.java
package com.mugil.visitor;
public class FranchiseStore implements Visitable{
private int totalBillAmt;
FranchiseStore(int item) {
totalBillAmt = item;
}
public int getTotalBillAmt() {
return totalBillAmt;
}
@Override
public double acceptDiscount(Visitor objVisitior) {
// TODO Auto-generated method stub
return 0;
}
}
RegularStore.java
package com.mugil.visitor;
public class RegularStore implements Visitable {
private int totalBillAmt;
RegularStore(int item) {
totalBillAmt = item;
}
public double acceptDiscount(Visitor visitor) {
return visitor.getDiscount(this);
}
public double getTotalBillAmt() {
return totalBillAmt;
}
}
LicensedStore.java
package com.mugil.visitor;
public class LicensedStore implements Visitable {
private int totalBillAmt;
LicensedStore(int item) {
totalBillAmt = item;
}
public double acceptDiscount(Visitor visitor) {
return visitor.getDiscount(this);
}
public double getTotalBillAmt() {
return totalBillAmt;
}
}
ClubCardVisitor.java
package com.mugil.visitor;
public class ClubCardVisitor implements Visitor
{
@Override
public double getDiscount(FranchiseStore objFranchiseStore) {
// TODO Auto-generated method stub
return 0.02;
}
@Override
public double getDiscount(RegularStore objRegularStore) {
// TODO Auto-generated method stub
return 0.03;
}
@Override
public double getDiscount(LicensedStore objLicensedStore) {
// TODO Auto-generated method stub
return 0.00;
}
}
PlatinumCardVisitor.java
package com.mugil.visitor;
public class PlatinumCardVisitor implements Visitor
{
@Override
public double getDiscount(FranchiseStore objFranchiseStore) {
// TODO Auto-generated method stub
return 0.05;
}
@Override
public double getDiscount(RegularStore objRegularStore) {
// TODO Auto-generated method stub
return 0.07;
}
@Override
public double getDiscount(LicensedStore objLicensedStore) {
// TODO Auto-generated method stub
return 0.03;
}
}
PremiumCardVisitor.java
package com.mugil.visitor;
public class PremiumCardVisitor implements Visitor {
@Override
public double getDiscount(FranchiseStore objFranchiseStore) {
// TODO Auto-generated method stub
return 0.03;
}
@Override
public double getDiscount(RegularStore objRegularStore) {
// TODO Auto-generated method stub
return 0.05;
}
@Override
public double getDiscount(LicensedStore objLicensedStore) {
// TODO Auto-generated method stub
return 0.02;
}
}
GetVisitorDiscount.java
package com.mugil.visitor;
public class GetVisitorDiscount
{
public static void main(String[] args)
{
int totalBillAmount = 500;
System.out.println("Discount for Club Card Visitor @ Franchise Store");
ClubCardVisitor objClubCardVisitor = new ClubCardVisitor();
FranchiseStore objFranchiseStore = new FranchiseStore(totalBillAmount);
double discountPct = objClubCardVisitor.getDiscount(objFranchiseStore);
double discountAmt = objClubCardVisitor.getDiscount(objFranchiseStore)*totalBillAmount;
double AmtAfterDis = totalBillAmount - discountAmt;
System.out.println("---------------------------------------------------");
System.out.println("Total Amount of Purchase " + totalBillAmount);
System.out.println("Discount Percentage " + discountPct*100 + "%");
System.out.println("Discount Amount " + discountAmt);
System.out.println("Total Amount after Discount " + AmtAfterDis);
}
}
Output
Discount for Club Card Visitor @ Franchise Store --------------------------------------------------- Total Amount of Purchase 500 Discount Percentage 2.0% Discount Amount 10.0 Total Amount after Discount 490.0