- Spring sits between the application classes and the O/R mapping tool, undertakes transactions, and manages connection objects.It translates the underlying persistence exceptions thrown by Hibernate to meaningful, unchecked exceptions of type DataAccessException. Moreover, Spring provides IoC and AOP, which can be used in the persistence layer
- Hibernate uses Template Pattern – To clean the code and provide more manageable code, Spring utilizes a pattern called Template Pattern. By this pattern, a template object wraps all of the boilerplate repetitive code. Then, this object delegates the persistence calls as a part of functionality in the template. In the Hibernate case, HibernateTemplate extracts all of the boilerplate code, such as obtaining a Session, performing transaction, and handing exceptions.
- With Spring, the HibernateTemplate object interacts with Hibernate. This object removes the boilerplate code from DAO implementations.Any invocation of one of HibernateTemplate’s methods throws the generic DataAccessException exception instead of HibernateException (a Hibernate-specific exception).Spring lets us demarcate transactions declaratively, instead of implementing duplicated transaction-management code.
- The HibernateTemplate class uses a SessionFactory instance internally to obtain Session objects for Hibernate interaction. Interestingly, you can configure the SessionFactory object via the Spring IoC container to be instantiated and injected into DAO objects.
- Spring provides its own exception hierarchy, which sits on the exception hierarchies of the O/R mapping tools.The Spring exception hierarchy is defined as a subclass of org.springframework.dao.DataAccessException. Spring catches any exception thrown in the underlying persistence technology and wraps it in a DataAccessException instance.The DataAccessException object is an unchecked exception, because it extends RuntimeException and you do not need to catch it if you do not want to.
- Spring provides distinct DAO base classes for the different data-access technologies it supports. When you use Hibernate with Spring, the DAO classes extend the Spring org.springframework.orm.hibernate3.support.HibernateDaoSupport class. This class wraps an instance of org.springframework.orm.hibernate3.HibernateTemplate, which in turn wraps an org.hibernate.SessionFactory instance.
org.springframework.orm.hibernate3.support.HibernateDaoSupport | org.springframework.orm.hibernate3.HibernateTemplate | org.hibernate.SessionFactory - HibernateException is thrown for any failure when directly interacting with Hibernate. When Spring is used, HibernateException is caught by Spring and translated to DataAccessException for any persistence failure. Both exceptions are unchecked, so you do not need to catch them if you don’t want to do.
-
DAO Implementation using DAOSupport
StudentDao.javaimport java.util.Collection; public interface StudentDao { public Student getStudent(long id); public Collection getAllStudents(); public Collection findStudents(String lastName); public void saveStudent(Student std); public void removeStudent(Student std); }Using DAOSupport Object
StudentDao.javaimport org.springframework.orm.hibernate3.support.HibernateDaoSupport; import java.util.Collection; public class HibernateStudentDao extends HibernateDaoSupport implements StudentDao { public Student getStudent(long id) { return (Student) getHibernateTemplate().get(Student.class, new Long(id)); } public Collection getAllStudents() { return getHibernateTemplate().find("from Student std order by std.lastName, std.firstName"); } public Collection findStudents(String lastName) { return getHibernateTemplate().find("from Student std where std.lastName like ?", lastName + "%"); } public void saveStudent(Student std) { getHibernateTemplate().saveOrUpdate(std); } public void removeStudent(Student std) { getHibernateTemplate().delete(std); } } - all of the persistent methods in the DAO class use the getHibernateTemplate() method to access the HibernateTemplate object.
- HibernateTemplate is a Spring convenience class that delegates DAO calls to the Hibernate Session API. This class exposes all of Hibernate’s Session methods, as well as a variety of other convenient methods that DAO classes may need. Because HibernateTemplate convenient methods are not exposed by the Session interface, you can use find() and findByCriteria() when you want to execute HQL or create a Criteria object.
- Using the HibernateDaoSupport class as the base class for all Hibernate DAO implementations would be more convenient, but you can ignore this class and work directly with a HibernateTemplate instance in DAO classes. To do so, define a property of HibernateTemplate in the DAO class, which is initialized and set up via the Spring IoC container.
-
DAO Implementation Using HibernateTemplate
import org.springframework.orm.hibernate3.HibernateTemplate; import java.util.Collection; public class HibernateStudentDao implements StudentDao { HibernateTemplate hibernateTemplate; public Student getStudent(long id) { return (Student) getHibernateTemplate().get(Student.class, new Long(id)); } public Collection getAllStudents() { return getHibernateTemplate().find("from Student std order by std.lastName, std.firstName"); } public Collection findStudents(String lastName) { return getHibernateTemplate().find("from Student std where std.lastName like "+ lastName + "%"); } public void saveStudent(Student std) { getHibernateTemplate().saveOrUpdate(std); } public void removeStudent(Student std) { getHibernateTemplate().delete(std); } public HibernateTemplate getHibernateTemplate() { return hibernateTemplate; } public void setHibernateTemplate(HibernateTemplate hibernateTemplate) { this.hibernateTemplate = hibernateTemplate; } } - The DAO class now has the setHibernateTemplate() method to allow Spring to inject the configured HibernateTemplate instance into the DAO object.Moreover, the DAO class can abandon the HibernateTemplate class and use the SessionFactory instance directly to interact with Hibernate.
Using SessionFactory Object
import org.hibernate.HibernateException; import org.hibernate.Session; import org.hibernate.Query; import org.hibernate.SessionFactory; import org.springframework.orm.hibernate3.SessionFactoryUtils; import java.util.Collection; public class HibernateStudentDao implements StudentDao { SessionFactory sessionFactory; public Student getStudent(long id) { Session session = SessionFactoryUtils.getSession(this.sessionFactory, true); try { return (Student) session.get(Student.class, new Long(id)); } catch (HibernateException ex) { throw SessionFactoryUtils.convertHibernateAccessException(ex); } finally { SessionFactoryUtils.closeSession(session); } } public Collection getAllStudents() { Session session = SessionFactoryUtils.getSession(this.sessionFactory, true); try { Query query = session.createQuery("from Student std order by std.lastName, std.firstName"); Collection allStudents = query.list(); return allStudents; } catch (HibernateException ex) { throw SessionFactoryUtils.convertHibernateAccessException(ex); } finally { SessionFactoryUtils.closeSession(session); } } public Collection getGraduatedStudents() { Session session = SessionFactoryUtils.getSession(this.sessionFactory, true); try { Query query = session.createQuery("from Student std where std.status=1"); Collection graduatedStudents = query.list(); return graduatedStudents; } catch (HibernateException ex) { throw SessionFactoryUtils.convertHibernateAccessException(ex); } finally { SessionFactoryUtils.closeSession(session); } } public Collection findStudents(String lastName) { Session session = SessionFactoryUtils.getSession(this.sessionFactory, true); try { Query query = session.createQuery("from Student std where std.lastName like ?"); query.setString(1, lastName + "%"); Collection students = query.list(); return students; } catch (HibernateException ex) { throw SessionFactoryUtils.convertHibernateAccessException(ex); } finally { SessionFactoryUtils.closeSession(session); } } public void saveStudent(Student std) { Session session = SessionFactoryUtils.getSession(this.sessionFactory, true); try { session.save(std); } catch (HibernateException ex) { throw SessionFactoryUtils.convertHibernateAccessException(ex); } finally { SessionFactoryUtils.closeSession(session); } } public void removeStudent(Student std) { Session session = SessionFactoryUtils.getSession(this.sessionFactory, true); try { session.delete(std); } catch (HibernateException ex) { throw SessionFactoryUtils.convertHibernateAccessException(ex); } finally { SessionFactoryUtils.closeSession(session); } } public void setSessionFactory(SessionFactory sessionFactory) { this.sessionFactory = sessionFactory; } } - In all of the methods above, the SessionFactoryUtils class is used to obtain a Session object. The provided Session object is then used to perform the persistence operation. SessionFactoryUtils is also used to translate HibernateException to DataAccessException in the catch blocks and close the Session objects in the final blocks. Note that this DAO implementation bypasses the advantages of HibernateDaoSupport and HibernateTemplate. You must manage Hibernate’s Session manually (as well as exception translation and transaction management) and implement much boilerplate code.
- org.springframework.orm.hibernate3.SessionFactoryUtils is a Spring helper class for obtaining Session, reusing Session within transactions, and translating HibernateException to the generic DataAccessException.
- In cases where you need to work directly with Session objects, you can use an implementation of the org.springframework.orm.hibernate3.HibernateCallback interface as the handler to work with Sessions.
-
An implicit implementation of HibernateCallback is created and its only doInHibernate() method is implemented. The doInHibernate() method takes an object of Session and returns the result of persistence operation, null if none. The HibernateCallback object is then passed to the execute() method of HibernateTemplate to be executed. The doInHibernate() method just provides a handler to work directly with Session objects that are obtained and used behind the scenes.
Using HibernateCallback
public void saveStudent(Student std) { HibernateCallback callback = new HibernateCallback() { public Object doInHibernate(Session session) throws HibernateException, SQLException { return session.saveOrUpdate(std); } }; getHibernateTemplate().execute(callback); }
Category Archives: Java
What is BeanFactory?
What is BeanFactory?
The BeanFactory is the actual container which instantiates, configures, and manages a number of beans.Let have a look at how spring works
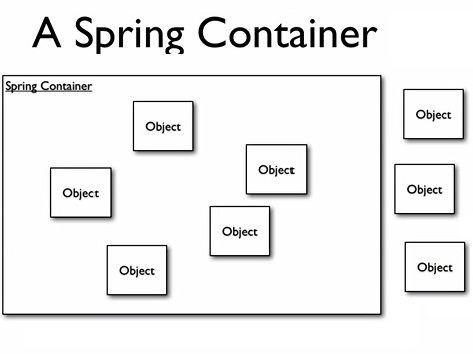
How it Works
- When the application is Deployed the Spring framework reads the xml file and creates the objects.Those are the objects which you see in the Spring Container
- Now when you try to refer any of these objects from the outside object using the new method it will throw an exception since or when you try to create a object using new method, the spring container has no idea about the object which you are trying to access
- Now to access the object in the container you will use the BeanFactory Objects
BeanFactory is represented by org.springframework.beans.factory.BeanFactory interface.It is the main and the basic way to access the Spring container.Other ways to access the spring container such as ApplicationContext,ListableBeanFactory, ConfigurableBeanFactory etc. are built upon this BeanFactory interface.
BeanFactory interface defines basic functionality for the Spring Container like
- It is built upon Factory Design Pattern
- provides DI / IOC mechanism for the Spring.
- It loads the beans definitions and their property descriptions from some configuration source (for example, from XML configuration file) .
- Instantiates the beans when they are requested like beanfactory_obj.getBean(“beanId”).
- Wire dependencies and properties for the beans according to their configuration defined in configuration source while instantiating the beans.
- Manage the bean life cycle by bean lifecycle interfaces and calling initialization and destruction methods.
Note that BeanFactory does not create the objects of beans immediately when it loads the configuration for beans from configuration source.Only bean definitions and their property descriptions are loaded. Beans themselves are instantiated and their properties are set only when they are requested such as by getBean() method.
Different BeanFactory Implementations:
XmlBeanFactory using Constructor:
Resource res = new FileSystemResource("c:/beansconfig.xml");
BeanFactory bfObj = new XmlBeanFactory(res);
MyBean beanObj= (MyBean) bfObj.getBean("mybean");
- The XmlBeanFactory takes the resource object as Parameter
- bfObj points to the Spring Container from which you try to fetch the object
- mybean is the ID of the Object specified in the XML File
- In the above case BeanFactory loads the beans lazily.BeanFactory will read bean definition of a bean with id “mybean” from beansconfig.xml file, instantiates it and return a reference to that.
- There are tow implementation of Resource Intefrace. one is org.springframework.core.io.FileSystemResource as seen above and other is org.springframework.core.io.ClassPathResource which loads Loads the resource from classpath(shown below).
ClassPathResource resorce = new ClassPathResource ("beansconfig.xml");
BeanFactory factory = new XmlBeanFactory(resource);
ClassPathXmlApplicationContext:
ClassPathXmlApplicationContext appContext = new ClassPathXmlApplicationContext(
new String[] {"applicationContext.xml", "applicationContext-part2.xml"});
//an ApplicationContext is also a BeanFactory.
BeanFactory factory = (BeanFactory) appContext;
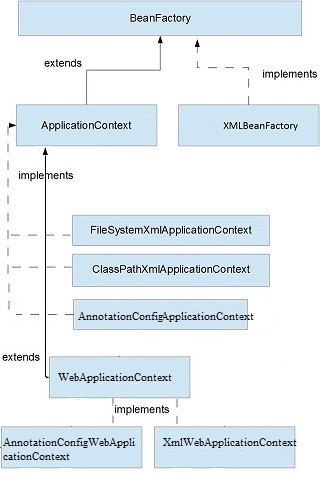
Note BeanFactory is not recomended for use in latest Spring versions. It is there only for backward compatability. ApplicationContext is preferred over this because ApplicationContext provides more advance level features which makes an application enterprise level application.
Spring – @Autowired
Autowiring vs new Object Keyword
| Autowiring | new Object() |
|---|---|
| decouples object creation and life-cycle from object binding and usage | Using new Keyword creates new Object everytime.The object graph grows over a period of time.Consider UserDaoImpl perhaps needs a Hibernate session, which needs a DataSource, which needs a JDBC connection – it quickly becomes a lot of objects that has to be created and initialized over and over again. When you rely on new in your code |
| Autowiring offers object at different scopes – Singleton, request and prototype | All objects are JVM Scope |
How Autowiring works
The autowiring happens when the application starts up, during the time of deployment.When it sees @Autowired, Spring will look for a class that matches the property in the applicationContext, and inject it automatically.
Lets see a example where the dependencies are resolved by XML and annotation
ApplicationContext.xml
<beans ...>
<bean id="userService" class="com.foo.UserServiceImpl"/>
<bean id="fooController" class="com.foo.FooController"/>
</beans>
When it sees @Autowired, Spring will look for a class that matches the property in the applicationContext, and inject it automatically. If you have more than 1 UserService bean, then you’ll have to qualify which one it should use.
FooController.java
public class FooController
{
// You could also annotate the setUserService method instead of this
@Autowired
private UserService userService;
// rest of class goes here
}
Things to Note while Autowiring
- Marks a constructor, field, setter method or config method as to be autowired by Spring’s dependency injection facilities.
- Only one constructor (at max) of any given bean class may carry this annotation, indicating the constructor to autowire when used as a Spring bean. Such a constructor does not have to be public.
- Fields are injected right after construction of a bean, before any config methods are invoked. Such a config field does not have to be public.
- •In the case of multiple argument methods, the ‘required’ parameter is applicable for all arguments.
Annotation or XML
For instance, if using Spring, it is entirely intuitive to use XML for the dependency injection portion of your application. This gets the code’s dependencies away from the code which will be using it, by contrast, using some sort of annotation in the code that needs the dependencies makes the code aware of this automatic configuration.
However, instead of using XML for transactional management, marking a method as transactional with an annotation makes perfect sense, since this is information a programmer would probably wish to know. But that an interface is going to be injected as a SubtypeY instead of a SubtypeX should not be included in the class, because if now you wish to inject SubtypeX, you have to change your code, whereas you had an interface contract before anyways, so with XML, you would just need to change the XML mappings and it is fairly quick and painless to do so.
I haven’t used JPA annotations, so I don’t know how good they are, but I would argue that leaving the mapping of beans to the database in XML is also good, as the object shouldn’t care where its information came from.If an annotation provides functionality and acts as a comment in and of itself, and doesn’t tie the code down to some specific process in order to function normally without this annotation, then go for annotations. For example, a transactional method marked as being transactional does not kill its operating logic, and serves as a good code-level comment as well. Otherwise, this information is probably best expressed as XML, because although it will eventually affect how the code operates, it won’t change the main functionality of the code, and hence doesn’t belong in the source files.
How auto wiring works in Spring
- All Spring beans are managed – they “live” inside a container, called “application context”.the application context is bootstrapped and all beans – autowired. In web applications this can be a startup listener.
- All application has an entry point to that context. Web applications have a Servlet, JSF uses a el-resolver
- the context instantiates the objects, not you. I.e. – you never make new UserServiceImpl() – the container finds each injection point and sets an instance there.
- applicationContext.xml you should enable the
- Apart from the @Autowired annotation, Spring can use XML-configurable autowiring. In that case all fields that have a name or type that matches with an existing bean automatically get a bean injected. In fact, that was the initial idea of autowiring – to have fields injected with dependencies without any configuration. Other annotations like @Inject, @Resource can also be used
Hibernate getResultList() returns same row multiple time
Problem
When using getResultList() to retrieve the Rows of the DB table there may be times where you would end up getting the same rows multiple times.
Why this Happens
Let’s have a table tblGroup the one below
| ParentGrp | GrpName |
|---|---|
| Finance | Accounts |
| Finance | Sales |
- You have 2 records in database.Both the records has Finance as value in parentGrp column
- Now when you run a select query to select parentGrp = ‘Finance’ you will get 2 records
- Lets query them WHERE parentGrp = ‘Finance’
- SQL Query returns 2 rows
- Hibernate loads first one, and puts into session, with parentGrp as a key.Now this will happen if you have specified it as @ID in entity class or you havent specified it while joining two tables in entity class.The object is placed into the result list.
- Hibernate loads second one, notices that an object with the same @Id is already in the session, and just places the reference into the result List. Row data are ignored.
- Now we have two copies of the same record
Solution:
We can solve this by introducing a primary key column something like tblGroup_pk_id.Now this helps to uniquely identify the records in the table so it won’t get overridden when the next rows retrieved.
Now the GrpId should be entitled with @ID annotation in the entity class.
| GrpId | ParentGrp | GrpName |
|---|---|---|
| 101 | Finance | Accounts |
| 102 | Finance | Sales |
Difference between createQuery vs createSQLQuery vs createCriteria
| createQuery() | createSQLQuery() | createCriteria() |
|---|---|---|
| Creates Query Object | Creates Query Object | Creates Criteria Object |
| Uses HQL Syntax | Uses DB Specific Syntax | Uses Entity Class |
| The Columns of the rows retrieved would be name of the POJO Model Class | The Columns of the rows retrieved would be name of Native DB fields | Create sql query using Criteria object for setting the query parameters |
| CRUD operation could be done | CRUD operation could be done | Only Read Operation is allowed |
| Supports Interoperability between different DB’s | Does not support Interoperability since the query format should be changed when the DB is changed | Supports Interoperability between different DB’s |
| Does not work without Model Class | Bean with columns of Table alone is Enough.No need for Entity class generation | Does not work without Model Class |
| No need for mapping between Entity class object and Table Columns | The Bean Objects should be mapped with table Columns | No need for mapping |
createQuery – session.createQuery()
------------------------------------------------------ **DB_TBL_Col(tblEmployee)**| **POJO(Employee)** EMP_ID | employeeID ------------------------------------------------------
Query query = session.createQuery("from Employee E where E.employeeID = 'A%'");
List<Person> persons = query.list();
How to generate Model Class Entities using JPA and Eclipse
Step 1:
Step 2:
Step 3:
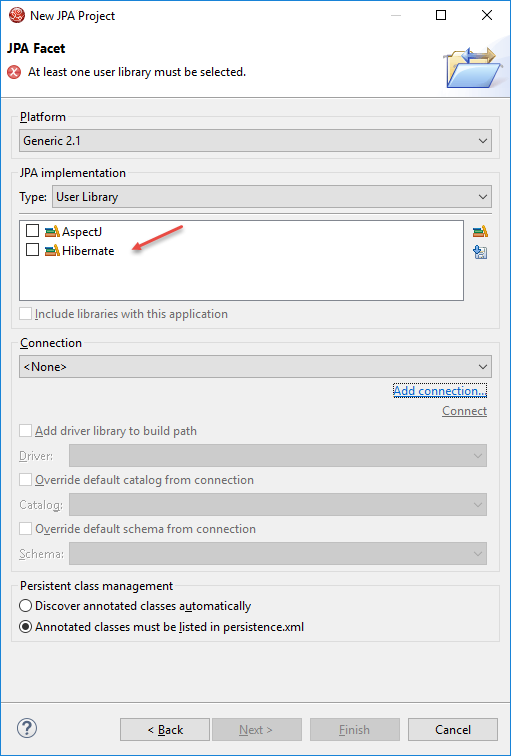
Step 4:
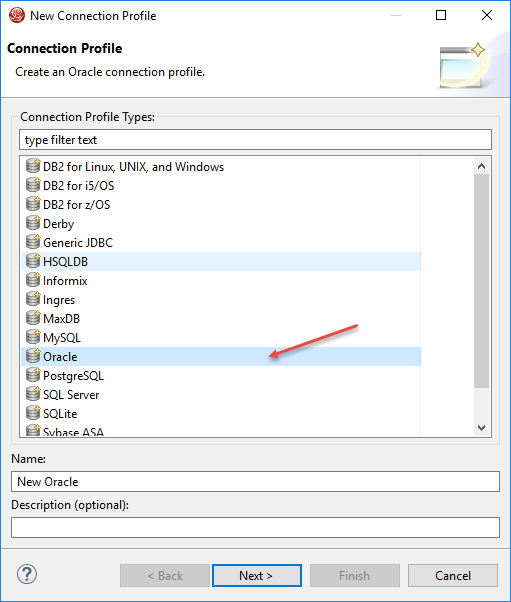
Step 5:
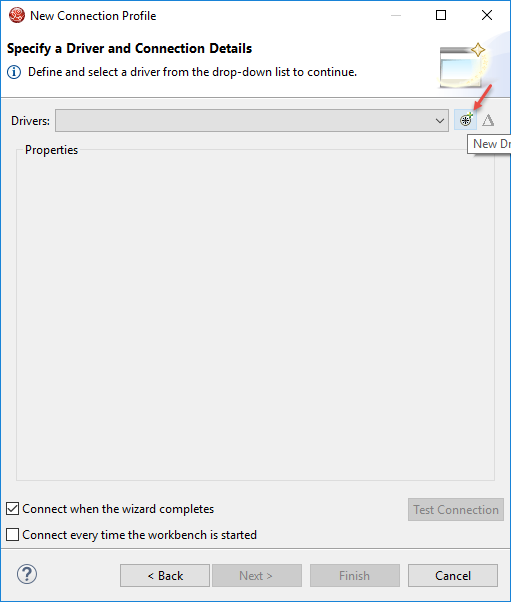
Step 6:
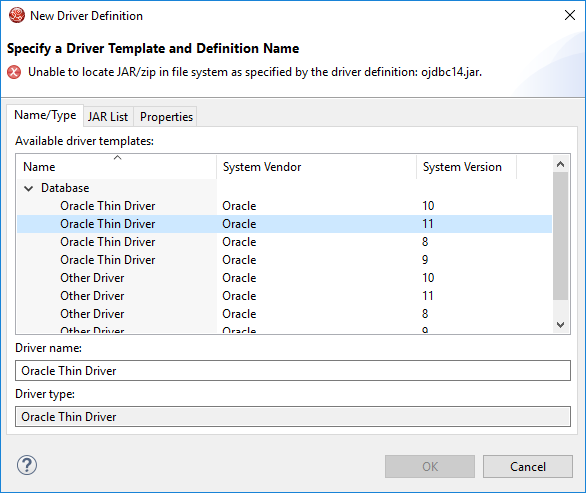
Step 7:
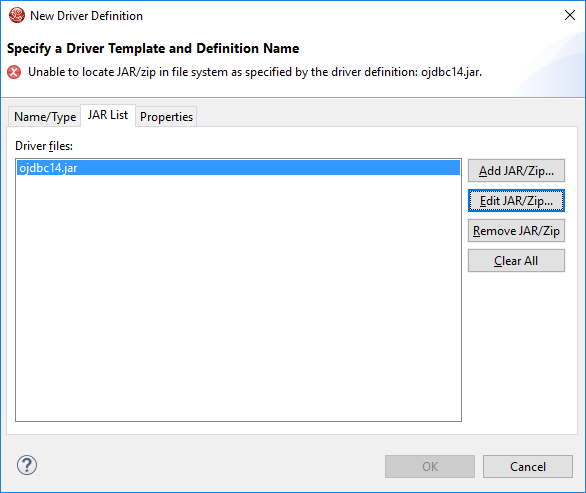
Step 8:
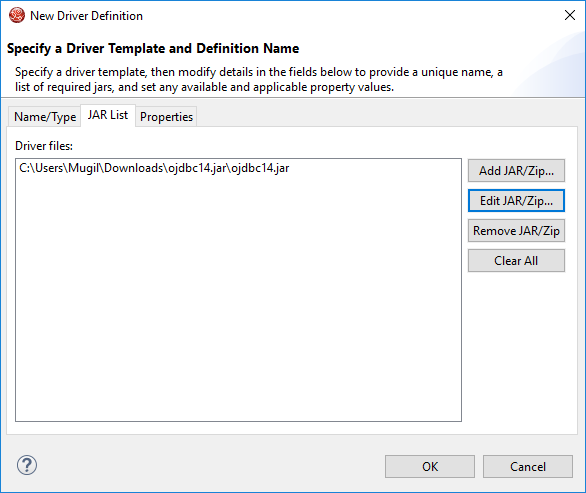
Step 9:
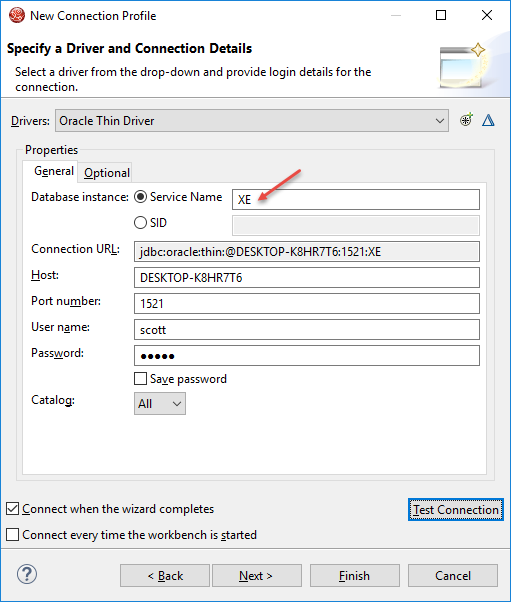
Step 10:
tnsnames.ora can be spotted at D:\Oracle\app\oracle\product\10.2.0\server\NETWORK\ADMIN
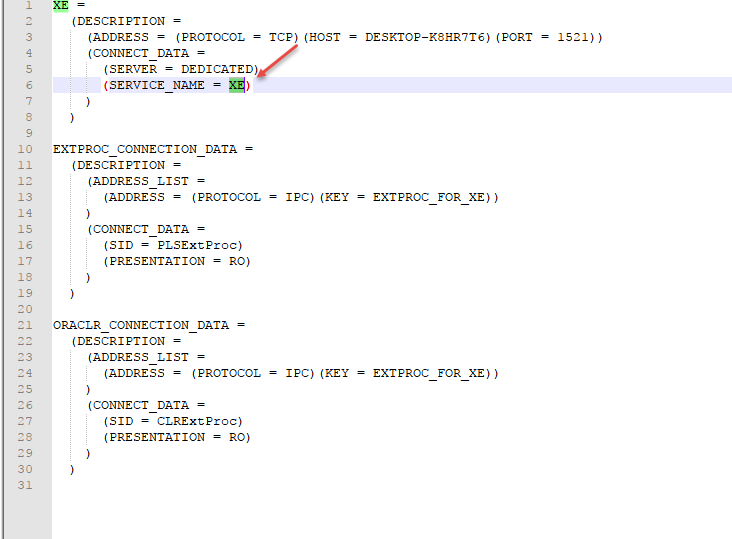
Step 11:
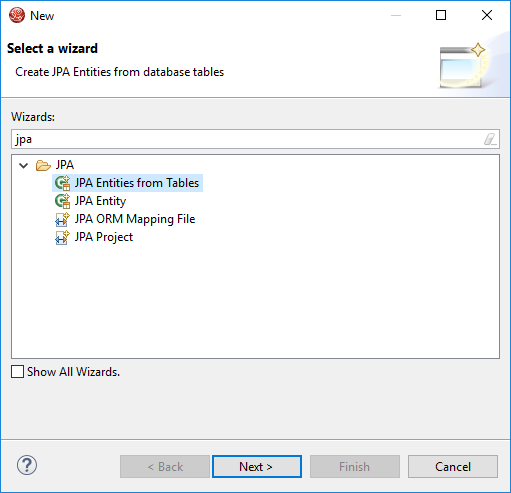
Step 12:
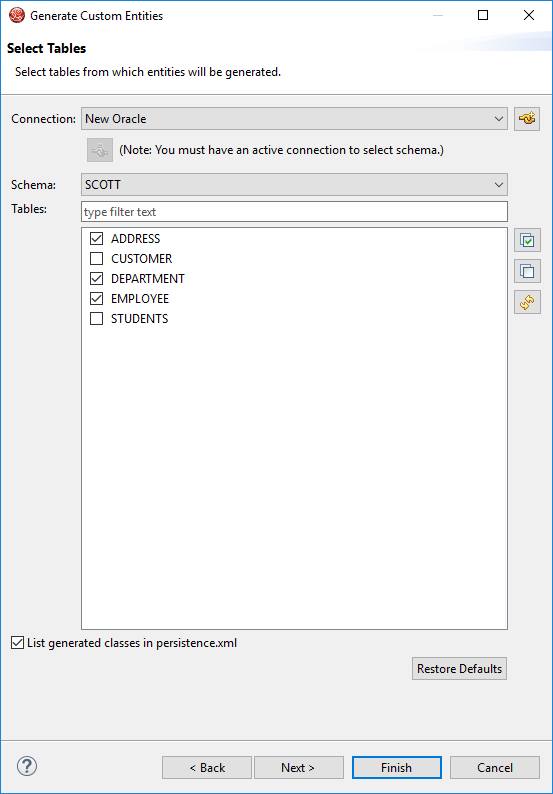
Step 13:
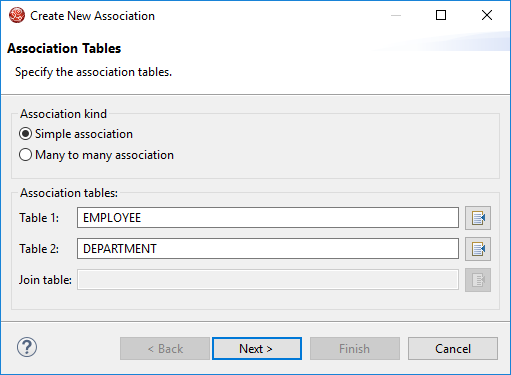
Step 14:
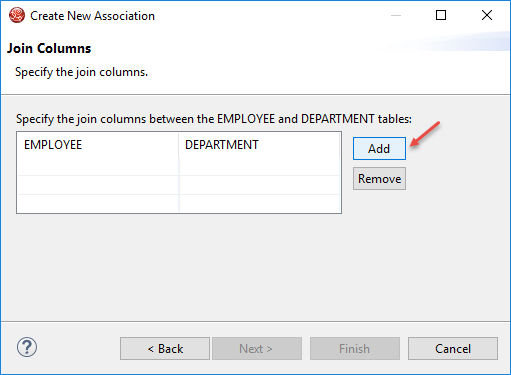
Step 15:
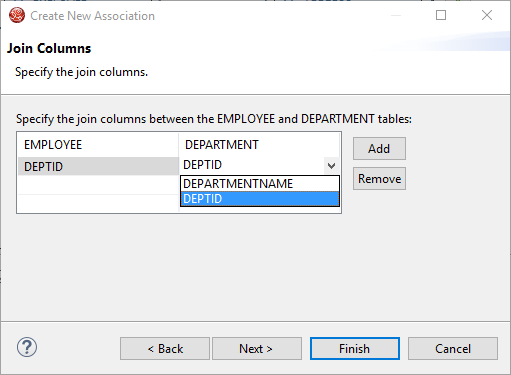
Step 16:
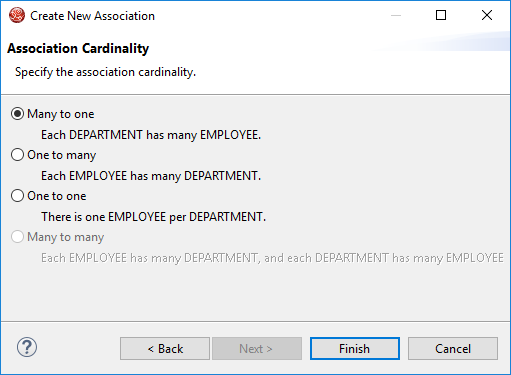
Step 17:
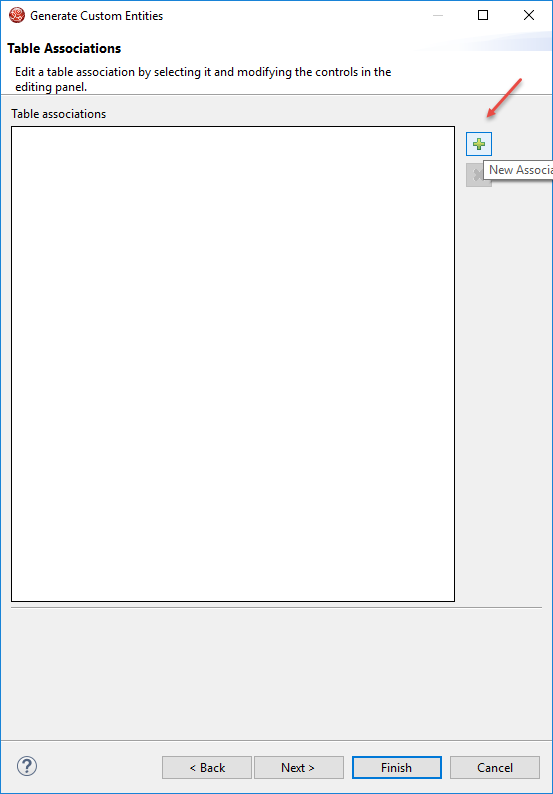
Step 18:
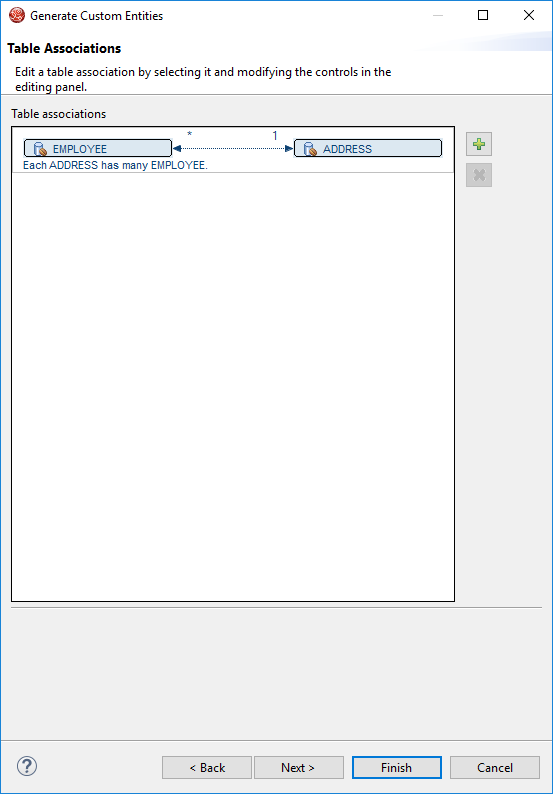
Step 19:
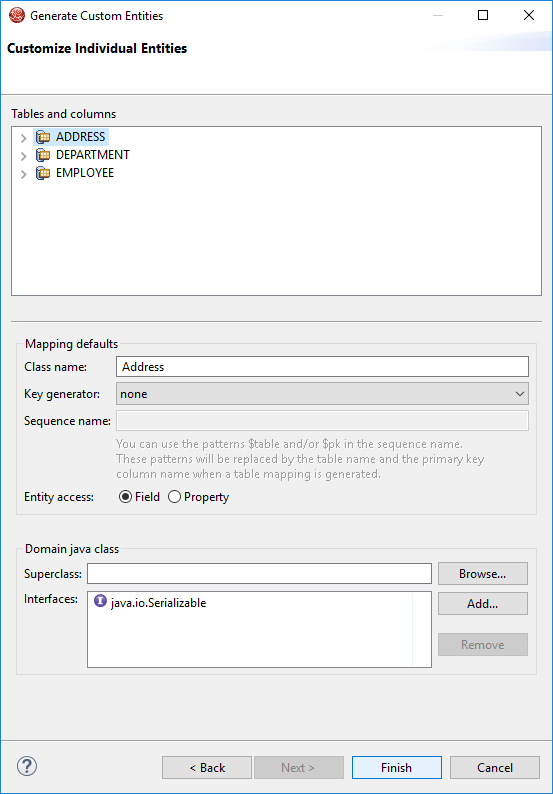
Step 20:
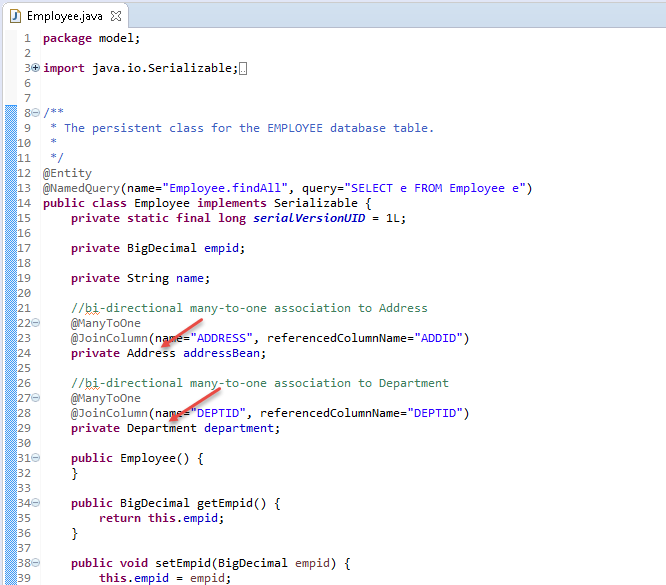
Step 21:
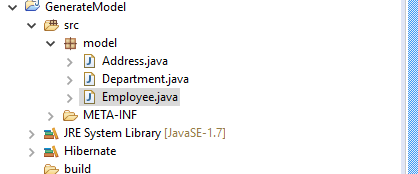
Reading Lines from Log Files – Batch Script
The below batch script helps to read the selected trailing lines from Log File
@echo off
cls
setlocal EnableDelayedExpansion
set "cmd=findstr /R /N "^^" C:\Users\Mugil\Desktop\test.txt | find /C ":""
for /f %%a in ('!cmd!') do set totalLines=%%a
rem echo "totalLines-"%totalLines%
@set linesToConsider=4
set /a lineToStart="%totalLines%-%linesToConsider%"
rem echo "lineToStart-"%lineToStart%
set content=
for /f "skip=%lineToStart% delims=" %%i in ('type C:\Users\Mugil\Desktop\test.txt') do set content=!content! %%i
@echo "content - "%content%
If NOT "%content%"=="%content:SUCCESS=%" (
echo Build Successful
) else (
echo Build Failed
)
pause
working with EntityManagerFactory – Best Practices
Working with EntityManagerFactory – Best Practices
- EntityManagerFactory instances are heavyweight objects. Each factory might maintain a metadata cache, object state cache, EntityManager pool, connection pool, and more. If your application no longer needs an EntityManagerFactory, you should close it to free these resources.
- When an EntityManagerFactory closes, all EntityManagers from that factory, and by extension all entities managed by those EntityManagers, become invalid.
- It is much better to keep a factory open for a long period of time than to repeatedly create and close new factories. Thus, most applications will never close the factory, or only close it when the application is exiting.
- Only applications that require multiple factories with different configurations have an obvious reason to create and close multiple EntityManagerFactory instances.
- Only one EntityManagerFactory is permitted to be created for each deployed persistence unit configuration. Any number of EntityManager instances may be created from a given factory.
- More than one entity manager factory instance may be available simultaneously in the JVM. Methods of the EntityManagerFactory interface are threadsafe.
Unidirectional and Bidirectional Mapping
Unidirectional – bidirectional relationship provides navigational access in one direction
Parent -----> Child
i.e you can go from parent to child, but you cannot go back from children to parent.
However, if there were no pointer to Parent in Child:
class Child { }
Bidirectional – bidirectional relationship provides navigational access in both directions
Parent <-----> Child
i.e you can go from a Parent to its child, and vice-versa: the parent knows about its child, the child knows about its parent
class Parent {
Child* children;
}
class Child {
Parent* parent;
}
Idle Scenarios
One to One unidirectional Mapping
employee knows the employer
One to One Bidirectional Mapping
employer knows the employee and employee knows the employer
One to Many unidirectional Mapping
employee has a skill in his skill set which is not used by other employees
One to Many bidirectional Mapping
employee has a skill in his skill set which is not used by other employees and
employer knows that employee has this skill in skill set
Many to One unidirectional Mapping
employees knows which employer he is going to work but employer has no idea about employee
employees will have employerId in their entity class but employer has no details of employee
Many to One bidirectional Mapping
Many employees work for one Employer. The employer knows about employee and employee knows about employer
employees will have employerId in their entity class but employer will have empid of employee
Many to Many unidirectional Mapping
Employee knows the employers he has worked for but employers does not know details of employee who worked for them
Many to Many bidirectional Mapping
Employee knows about the employers he has worked for and employers knows about employee who has worked for them.
Getting Count in JPA
JPA COUNT returns a Long
When extracting the count from the table JPA returns long based on the type of query used.
JPQL
Query query = em.createQuery("SELECT COUNT(p) FROM PersonEntity p " );
query.getSingleResult().getClass().getCanonicalName() --> java.lang.Long
Native Query
Query query = em.createNativeQuery("SELECT COUNT(*) FROM PERSON");
query.getSingleResult().getClass().getCanonicalName() --> java.math.BigInteger
If it is Native Query big Integer is returned or if it is JPQL then Long is returned.
So before assigning to Integer the value should be typecasted.
int count = ((Number)arrCount.get[0]).intValue(); System.out.println(count);
Needs to be Removed
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:context="http://www.springframework.org/schema/context"
xmlns:tx="http://www.springframework.org/schema/tx" xmlns:jpa="http://www.springframework.org/schema/data/jpa"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-3.0.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/tx
http://www.springframework.org/schema/data/jpa http://www.springframework.org/schema/data/jpa/spring-jpa.xsd">
<context:annotation-config />
<context:component-scan base-package="" />
<tx:annotation-driven transaction-manager="transactionManager"/>
<bean id="transactionManager" class="org.springframework.orm.jpa.JpaTransactionManager">
<property name="entityManagerFactory" ref="entityManagerFactory" />
</bean>
<!-- Configure the entity manager factory bean -->
<bean id="entityManagerFactory"
class="org.springframework.orm.jpa.LocalContainerEntityManagerFactoryBean">
<property name="dataSource" ref="dataSource" />
<property name="jpaVendorAdapter" ref="hibernateJpaVendorAdapter" />
<!-- Set JPA properties -->
<property name="jpaProperties">
<props>
<prop key="hibernate.dialect">org.hibernate.dialect.Oracle10g</prop>
</props>
</property>
<!-- Set base package of your entities -->
<property name="packagesToScan" value="com.mugil.org.model" />
</bean>
<beans:bean id="dbDataSource" class="org.springframework.jndi.JndiObjectFactoryBean" scope="singleton" lazy-init="true">
<beans:property name="jndiName" value="java:jboss/datasources/TurboDS"/>
</beans:bean>
</beans>