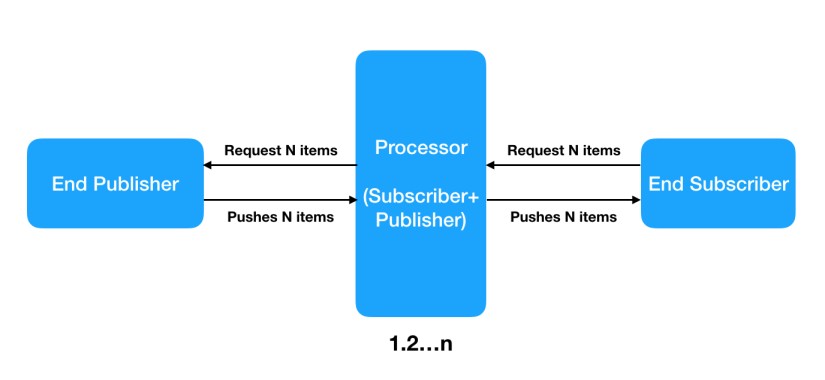
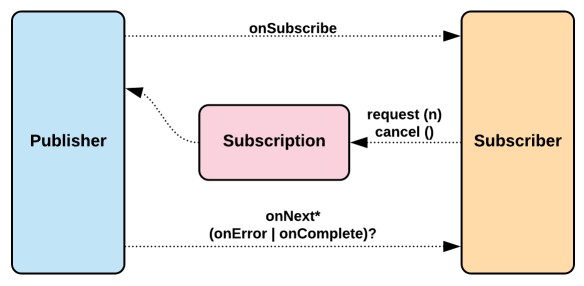
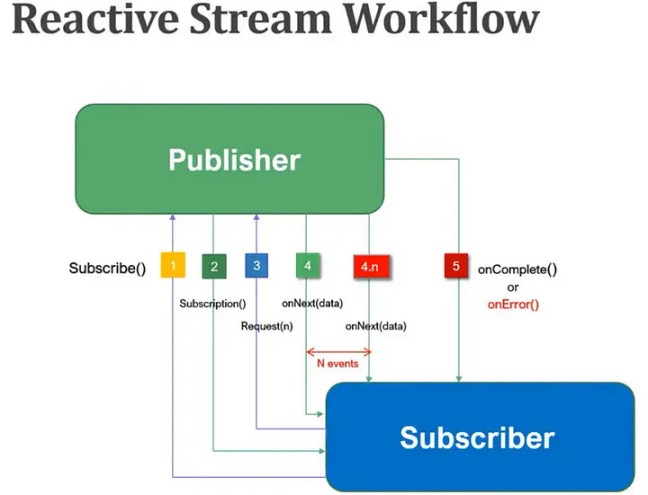
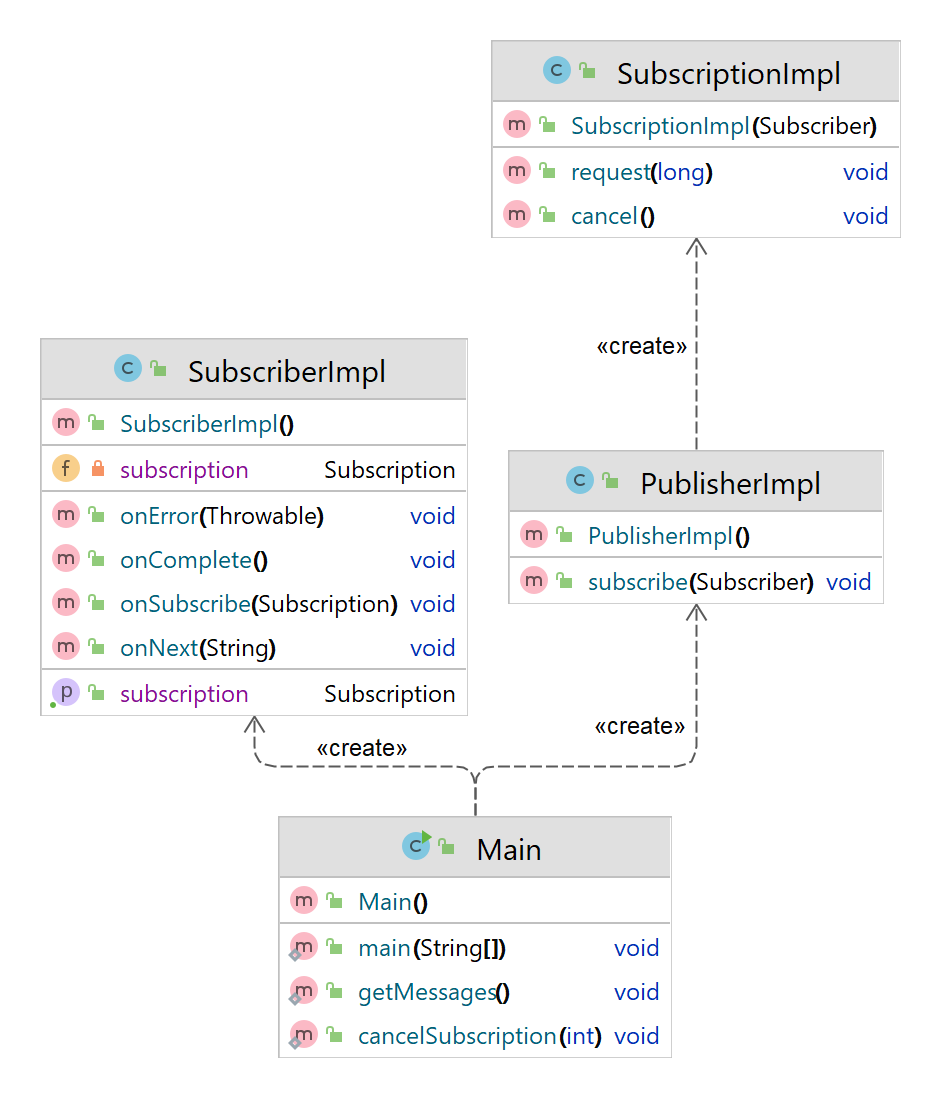
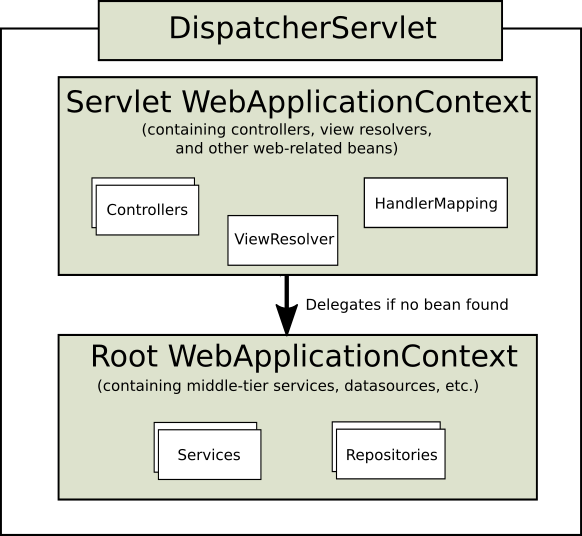
Its to overcome monotony behavior. If you are asking for Apple(from Apple.java) you would be served apple object. If you are asking for Mango(from Mango.java) you would be served mango object. Now in case, you are having Fruit and now you are asking Fruit(from Fruit.java) you would be served either apple or mango. Lets take a simple example as below
- I have a banking application where I have Account Interface with calculateIntereest Method
- I have different account types like SavingsAccount, PersonalLoanAccount and vehicleLoanAccount, HousingLoanAccount
- I have a Customer class where he would own a particular account type which wont be known until runtime
Accounts.java
package com.mugil.core;
public interface Accounts
{
public Integer calculateInterest();
}
SavingsAccount.java
package com.mugil.core;
public class SavingsAccount implements Accounts
{
public Integer calculateInterest()
{
return 8;
}
}
Customer.java
package com.mugil.core;
public class Customer {
Accounts accountType;
public Customer(Accounts paccountType) {
this.accountType = paccountType;
}
public Accounts getAccountType() {
return accountType;
}
public void setAccountType(Accounts accountType) {
this.accountType = accountType;
}
}
GetInterestFactory.java
package com.mugil.core;
public class GetInterestFactory {
Accounts objAccount = null;
public static void main(String[] args) {
GetInterestFactory objGetInterest = new GetInterestFactory();
objGetInterest.showInterestRate();
}
public void showInterestRate() {
String strAccType = "Savings";
switch (strAccType) {
case "Savings":
this.objAccount = new SavingsAccount();
break;
case "Vehicle":
this.objAccount = new VehicleLoanAccount();
break;
default:
this.objAccount = new SavingsAccount();
break;
}
System.out.println("Interest Rate - " + this.objAccount.calculateInterest());
}
}
Output
Interest Rate - 8
- In the above java code we decide the Account Type only when the switch case is executed
- Until then the account type is kept as generic value using interface
Now what spring does is the same code can be rewritten to determine the Account Type during runtime in setters and constructors as below
- I have created a new class VehicleLoanAccount.java which has a different interest rate
- Now I am going to decide the account type in the Person.java in its constructor as below
VehicleLoanAccount.java
package com.mugil.core;
public class VehicleLoanAccount implements Accounts {
public Integer calculateInterest() {
return 11;
}
}
Dependency Injection without Spring using Java Constructor
GetInterestConsWithoutSpring .java
package com.mugil.core;
public class GetInterestConsWithoutSpring {
public static void main(String[] args) {
Customer objPerson = new Customer(new SavingsAccount());
System.out.println("Interest Rate - " + objPerson.getAccountType().calculateInterest());
}
}
Output
Interest Rate - 11
- Now I am going to decide the account type in the GetInterest.java in its setter method
- I would be passing the value of the actual type inside the setter at runtime to decide the account type
- The Only thing which I have changed in the addition of new constructor to the Customer Class
- Setter method would be passed with specific account type during runtime
Customer.java
package com.mugil.core;
public class Customer {
Accounts accountType;
public Customer(Accounts paccountType) {
this.accountType = paccountType;
}
public Customer() {}
public Accounts getAccountType() {
return accountType;
}
public void setAccountType(Accounts accountType) {
this.accountType = accountType;
}
}
Dependency Injection without Spring using Setter Method
GetInterestSettWithoutSpring .java
package com.mugil.core;
public class GetInterestSettWithoutSpring {
public static void main(String[] args) {
Customer customer = new Customer();
customer.setAccountType(new SavingsAccount());
System.out.println("Interest Rate - " + customer.getAccountType().calculateInterest());
}
}
Output
Interest Rate - 8
In Spring we can let the container create the bean in two ways
- Bean definition in XML
- Bean definition using @Component
- Bean definition using Java
beans.xml
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-2.5.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context-2.5.xsd">
<bean id="customer" class="com.mugil.core.Customer" autowire="constructor">
</bean>
<bean id="savingsType" class="com.mugil.core.SavingsAccount"/>
<bean id="vehicleLoanAccount" class="com.mugil.core.VehicleLoanAccount"/>
</beans>
context:component-scan used for detecting bean
beans.xml
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-2.5.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context-2.5.xsd">
<context:annotation-config />
<context:component-scan base-package="com.mugil.core"></context:component-scan>
</beans>
@Component marking bean
Customer.java
package com.mugil.core;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
@Component
public class Customer
{
@Autowired
@Qualifier("savings")
Accounts accountType;
.
.
.
}
@Component marking bean
SavingsAccount.java
package com.mugil.core;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.stereotype.Component;
@Component
@Qualifier("savings")
public class SavingsAccount implements Accounts
{
public Integer calculateInterest()
{
return 9;
}
}
Now, what if we do the same thing from XML and using annotations. Spring offers 3 ways by which dependency injection could be done
- XML
- Constructor
- Setter
- Autowiring
- byType
- byName
- Constructor
- No
- Annotation Based
- byType
- byName
- Java Based
Constructor Based – Dependency Injection using XML
- In the below code beans are loaded when the application is deployed and the JVM starts
- The beans are uniquely identified using their IDS, in our case it is customer
- The parameter for constructor is defined inside constructor-arg in XML
Beans.xml
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-3.0.xsd">
<bean id="customer" class="com.mugil.core.Customer">
<constructor-arg>
<bean id="savingAccount" class="com.mugil.core.SavingsAccount" />
</constructor-arg>
</bean>
</beans>
GetInterestConsWithSpring.xml
package com.mugil.core;
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
public class GetInterestConsWithSpring {
public static void main(String[] args) {
ApplicationContext context = new ClassPathXmlApplicationContext("SpringBeans.xml");
Customer customer = (Customer) context.getBean("customer");
System.out.println("Interest Rate - " + customer.getAccountType().calculateInterest());
}
}
Output
Interest Rate - 8
Setter Based – Dependency Injection using XML
- For setter injection the only things we need to change is XML
- XML should be modified to take value by setter rather than constructor as before using property tag
Beans.xml
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-3.0.xsd">
<bean id="customer" class="com.mugil.core.Customer">
<property name="accountType" ref="savingAccount" />
</bean>
<bean id="savingAccount" class="com.mugil.core.SavingsAccount" />
</beans>
GetInterestSettWithSpring.xml
package com.mugil.core;
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
public class GetInterestSettWithSpring {
public static void main(String[] args) {
ApplicationContext context = new ClassPathXmlApplicationContext(
"SpringBeans.xml");
Customer customer = (Customer) context.getBean("customer");
System.out.println("Interest Rate - " + customer.getAccountType().calculateInterest());
}
}
Output
Interest Rate - 8
- In autoWiring byName the Name of the Instance Varable(accountType) and the ID of the bean in XML should be same
- If there is no bean matching the name is found it will throw NullPointerException
Customer.java
package com.mugil.core;
public class Customer {
Accounts accountType;
public Customer(Accounts paccountType) {
this.accountType = paccountType;
}
public Customer() {}
public Accounts getAccountType() {
return accountType;
}
public void setAccountType(Accounts accountType) {
this.accountType = accountType;
}
}
Beans.xml
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-3.0.xsd">
<bean id="customer" class="com.mugil.core.Customer" autowire="byName">
</bean>
<bean id="accountType" class="com.mugil.core.SavingsAccount"/>
<bean id="vehicleLoanAccount" class="com.mugil.core.VehicleLoanAccount"/>
</beans>
Output
Interest Rate - 9
Beans.xml
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-3.0.xsd">
<bean id="customer" class="com.mugil.core.Customer" autowire="byName">
</bean>
<bean id="savingAccount" class="com.mugil.core.SavingsAccount"/>
<bean id="vehicleLoanAccount" class="com.mugil.core.VehicleLoanAccount"/>
</beans>
Output
Exception in thread "main" java.lang.NullPointerException
at com.mugil.core.GetInterestConstAutoWiringXML.main(GetInterestConstAutoWiringXML.java:13)
- In autoWiring is byType then there should be at least one bean defined for the matching type, in our case it is Accounts
- If there is no bean defined of the type then it will throw null pointer exception
- If there is more than one matching bean of the same type is found it will throw No unique bean of type
Beans.xml
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-3.0.xsd">
<bean id="customer" class="com.mugil.core.Customer" autowire="byType">
</bean>
<bean id="savingsType" class="com.mugil.core.SavingsAccount"/>
</beans>
Output
Interest Rate - 9
Beans.xml
No bean of right Type is defined in XML
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-3.0.xsd">
<bean id="customer" class="com.mugil.core.Customer" autowire="byType">
</bean>
</beans>
Output
Exception in thread "main" java.lang.NullPointerException
at com.mugil.core.GetInterestConstAutoWiringXML.main(GetInterestConstAutoWiringXML.java:13)
Beans.xml
More than one bean of same type defined
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-3.0.xsd">
<bean id="customer" class="com.mugil.core.Customer" autowire="byType">
</bean>
<bean id="savingsType" class="com.mugil.core.SavingsAccount"/>
<bean id="vehicleLoanAccount" class="com.mugil.core.VehicleLoanAccount"/>
</beans>
Output
Exception in thread "main" org.springframework.beans.factory.UnsatisfiedDependencyException: Error creating bean with name 'customer' defined in class path resource [SpringBeans.xml]: Unsatisfied dependency expressed through bean property 'accountType': : No unique bean of type [com.mugil.core.Accounts] is defined: expected single matching bean but found 2: [accountType, vehicleLoanAccount]; nested exception is org.springframework.beans.factory.NoSuchBeanDefinitionException: No unique bean of type [com.mugil.core.Accounts] is defined: expected single matching bean but found 2: [accountType, vehicleLoanAccount]
- In autoWiring using Constructor spring tries to find bean using type.In our case it is Account type
- If there is no bean defined of the type then spring will not guess and it will throw null pointer exception
- If there is more than one matching bean then spring will not guess and it will throw null pointer exception
- If there is more than one constructor spring wont guess the bean and it will throw null pointer exception
Beans.xml
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-3.0.xsd">
<bean id="customer" class="com.mugil.core.Customer" autowire="constructor">
</bean>
<bean id="savingsType" class="com.mugil.core.SavingsAccount"/>
</beans>
Output
Interest Rate - 9
Beans.xml
Two bean of same type in constructor injection
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-3.0.xsd">
<bean id="customer" class="com.mugil.core.Customer" autowire="constructor">
</bean>
<bean id="savingsType" class="com.mugil.core.SavingsAccount"/>
<bean id="vehicleLoanAccount" class="com.mugil.core.VehicleLoanAccount"/>
</beans>
Beans.xml
No bean of matching type in constructor injection
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-3.0.xsd">
<bean id="customer" class="com.mugil.core.Customer" autowire="constructor">
</bean>
</beans>
Output
Exception in thread "main" java.lang.NullPointerException
at com.mugil.core.GetInterestConstAutoWiringXML.main(GetInterestConstAutoWiringXML.java:13)
When the bean is configured to autowire by autodetect spring will attempt to autowire by constructor first.If no suitable constructor to bean is found then spring will attempt to autowire byType.
Beans.xml
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-3.0.xsd">
<bean id="customer" class="com.mugil.core.Customer" autowire="autodetect">
</bean>
</beans>
- In Annotation based autowiring the beans would be injected by xml and would be available in container
- context:annotation-config is used to activate annotations in beans already registered in the application context (no matter if they were defined with XML or by package scanning)
- Now by using @Autowired tag we inject the bean as dependency where it is required.It is used either over variable in class or over setter or over constructor
- The default @Autowired decides the bean based on its type.If more than one bean if found it will throw no unique bean found exception.If no bean found it will throw nullpointer exception
- Incase of more than one bean of same type, we can narrow down the selection by using @Qualifier annotation and converting to byName @Autowiring
Beans.xml
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-2.5.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context-2.5.xsd">
<context:annotation-config />
<bean id="customer" class="com.mugil.core.Customer" autowire="constructor">
</bean>
<bean id="savingsType" class="com.mugil.core.SavingsAccount"/>
</beans>
Customer.java
package com.mugil.core;
import org.springframework.beans.factory.annotation.Autowired;
public class Customer
{
@Autowired
private Accounts accountType;
public Customer(Accounts paccountType) {
this.accountType = paccountType;
}
public Customer() {}
public Accounts getAccountType() {
return accountType;
}
public void setAccountType(Accounts accountType) {
this.accountType = accountType;
}
}
- In the below code we have two bean of same type
- Using @autowired would try to find bean byType.Since there are two beans it would throw no unique bean found exception
- Now we need to use @Qualifier passing the name (or) id of the bean as parameter
- Incase only Id of bean is there then same would be taken for name, If Name is there then name of bean would be given preference, incase no bean matches name then Id would be given preference
Beans.xml
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-2.5.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context-2.5.xsd">
<context:annotation-config />
<bean id="customer" class="com.mugil.core.Customer" autowire="constructor">
</bean>
<bean name="savings" id="savingsType" class="com.mugil.core.SavingsAccount"/>
<bean name="vehicle" id="vehicleLoanAccount" class="com.mugil.core.VehicleLoanAccount"/>
</beans>
Customer.java
package com.mugil.core;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
public class Customer
{
@Autowired
@Qualifier("savings")
Accounts accountType;
.
.
.
}
The below code will work by taking bean id into consideration despite the name doesn’t match.
Customer.java
package com.mugil.core;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
public class Customer
{
@Autowired
@Qualifier("savingsType")
Accounts accountType;
.
.
.
}
It will not throw exception during compilation but during runtime it will throw bean name already in use exception
Output
Exception in thread "main" org.springframework.beans.factory.parsing.BeanDefinitionParsingException: Configuration problem: Bean name 'savings' is already used in this file
Offending resource: class path resource [SpringBeans.xml]
- Eclipse will complain for violating ID should be unique and you are violating
- If you build the code still builds but when you run will endup with Caused by: org.xml.sax.SAXParseException; lineNumber: 13; columnNumber: 69; cvc-id.2: There are multiple occurrences of ID value ‘savingsType’
Beans.xml
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-2.5.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context-2.5.xsd">
<context:annotation-config />
<bean id="customer" class="com.mugil.core.Customer" autowire="constructor">
</bean>
<bean id="savingsType" class="com.mugil.core.SavingsAccount"/>
<bean id="savingsType" class="com.mugil.core.VehicleLoanAccount"/>
</beans>
- We can make spring to detect beans on its own by using @component annotation rather then defining in XML with bean tags
- Using context:component-scan with base package pointed to beans package will load the bean marked with @component annotation
- If there is bean of one type then it would work fine during autowiring, if there is more than one bean of same type then we should uniquely identify the bean using @qualifier annotation
- @qualifier annotation should be used both in the place where the bean is referred and also in the place where it is defined.In our case it is Customer.java and SavingsAccount.java
Beans.xml
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-2.5.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context-2.5.xsd">
<context:annotation-config />
<context:component-scan base-package="com.mugil.core"></context:component-scan>
</beans>
Customer.java
package com.mugil.core;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
@Component
public class Customer
{
@Autowired
@Qualifier("savings")
Accounts accountType;
.
.
.
}
SavingsAccount.java
package com.mugil.core;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.stereotype.Component;
@Component
@Qualifier("savings")
public class SavingsAccount implements Accounts
{
public Integer calculateInterest()
{
return 9;
}
}