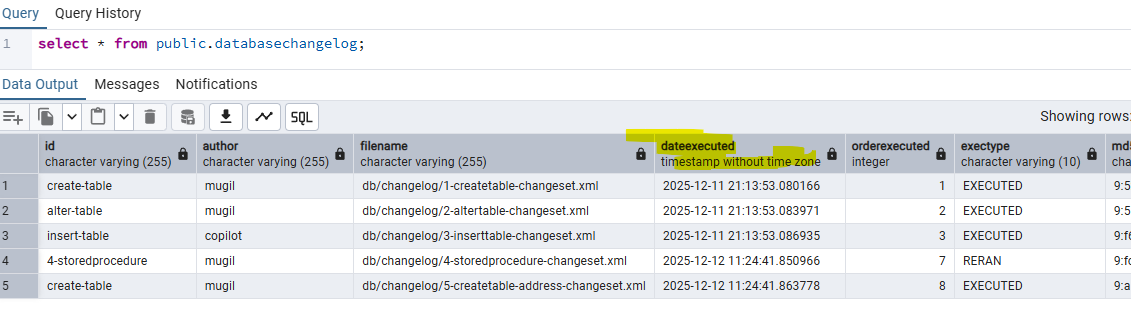
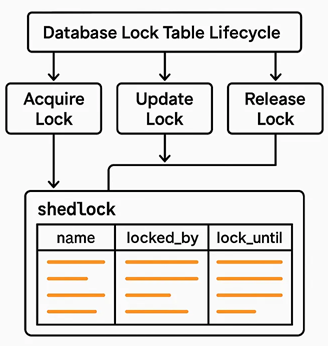
Simple Shedlock Code
pom.xml
<dependency> <groupId>net.javacrumbs.shedlock</groupId> <artifactId>shedlock-spring</artifactId> <version>5.13.0</version> </dependency> <dependency> <groupId>net.javacrumbs.shedlock</groupId> <artifactId>shedlock-provider-jdbc-template</artifactId> <version>5.13.0</version> </dependency>
ShedLockConfig.java
import net.javacrumbs.shedlock.core.LockProvider;
import net.javacrumbs.shedlock.provider.jdbctemplate.JdbcTemplateLockProvider;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.jdbc.core.JdbcTemplate;
import javax.sql.DataSource;
@Configuration
public class ShedLockConfig {
@Bean
public LockProvider lockProvider(DataSource dataSource) {
return new JdbcTemplateLockProvider(
JdbcTemplateLockProvider.Configuration.builder()
.withJdbcTemplate(new JdbcTemplate(dataSource))
.withTableName("empmgmt.shedlock")
.build()
);
}
}
ShedlockDemoApplication.java
import net.javacrumbs.shedlock.spring.annotation.EnableSchedulerLock;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.scheduling.annotation.EnableScheduling;
@SpringBootApplication
@EnableScheduling
@EnableSchedulerLock(defaultLockAtMostFor = "PT4M")
public class ShedlockDemoApplication {
public static void main(String[] args) {
SpringApplication.run(ShedlockDemoApplication.class, args);
}
}
PostFetchScheduler.java
fetchPosts method is called every minute
@Component
class PostFetchScheduler {
final PostFetchService postFetchService;
PostFetchScheduler(PostFetchService postFetchService) {
this.postFetchService = postFetchService;
}
@Scheduled(cron = "0 */1 * ? * *")
@SchedulerLock(name = "fetchPosts", lockAtMostFor = "PT2M", lockAtLeastFor = "PT1M")
void fetchPosts() {
postFetchService.fetchPosts();
}
}
How to run the code
- Shedlock table should be created manually in database
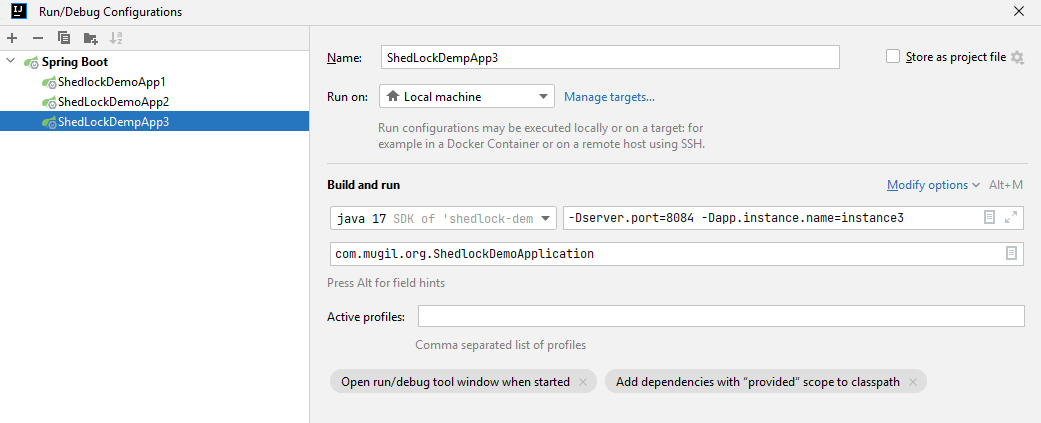
CREATE TABLE shedlock ( name VARCHAR(64) NOT NULL, -- lock name lock_until TIMESTAMP NOT NULL, -- time until lock is valid locked_at TIMESTAMP NOT NULL, -- time when lock was acquired locked_by VARCHAR(255) NOT NULL, -- identifier of the node that holds the lock PRIMARY KEY (name) ); - Start multiple instance by supplying server.port and instance name as parameter
- First instance would create table in DB for posts for code in repo
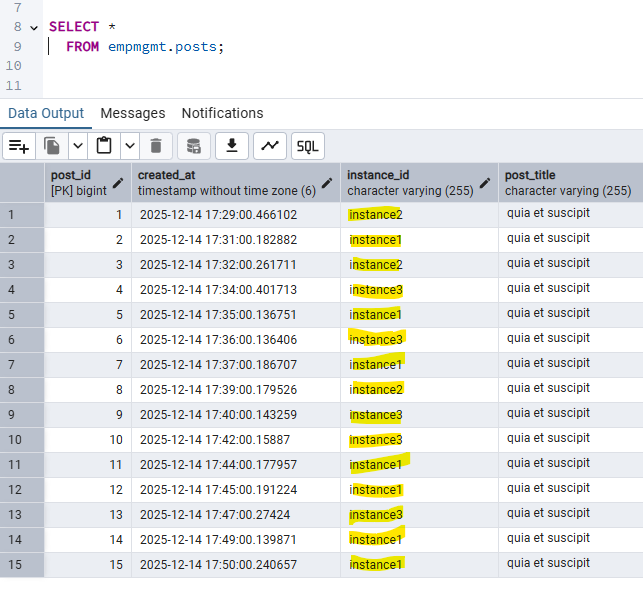
Output
FAQ
Why we are defining lock timing at 2 places?
@EnableSchedulerLock(defaultLockAtMostFor = "PT4M")
vs
@SchedulerLock(name = "fetchPosts", lockAtMostFor = "PT2M", lockAtLeastFor = "PT1M")
@EnableSchedulerLock sets defaults for all tasks. A fallback setting for all tasks.
@SchedulerLock gives per-task overrides with more precise control. Fine-grained control, overriding the default for specific jobs.