| Supplier |
Accounts.java
@FunctionalInterface
public interface Accounts{
abstract String showAccountType();
}
AccountImpl.java
public class AccountImpl {
public static void main(String[] args) {
//Implementation of Custom Supplier Method for Accounts Interface
Accounts squareRoot = () -> "Hi there";
System.out.println(squareRoot.showAccountType());
}
}
The above code could be expanded as below using Anonymous Inner Class
public class AccountImpl {
public static void main(String[] args) {
Accounts squareRoot = new Accounts() {
@Override
public String showAccountType() {
return "Hi there";
}
};
System.out.println(squareRoot.showAccountType());
}
}
|
| Consumer |
Accounts.java
@FunctionalInterface
public interface Accounts {
abstract void showAccountType(String strAccType);
}
AccountImpl.java
public class AccountImpl {
public static void main(String[] args) {
//Implementation of Custom Consumer Method for Accounts Interface
Accounts squareRoot = (strAccType) -> System.out.println(strAccType);
squareRoot.showAccountType("Savings");
}
}
The above code could be expanded as below using Anonymous Inner Class
public class AccountImpl {
public static void main(String[] args) {
Accounts squareRoot = new Accounts() {
@Override
public void showAccountType(String strAccType) {
System.out.println(strAccType);
}
};
}
}
|
| Predicate |
Accounts.java
@FunctionalInterface
public interface Accounts{
abstract boolean showAccountType(String accountType);
}
AccountImpl.java
public class AccountImpl {
public static void main(String[] args) {
//Implementation of Custom Predicate Method for Accounts Interface
Accounts squareRoot = (accountType) -> {
if ("Savings" == accountType)
return true;
else
return false;
};
if (squareRoot.showAccountType("Savings"))
System.out.println("Savings");
else
System.out.println("Invalid Account");
}
}
The above code could be expanded as below using Anonymous Inner Class
public class AccountImpl {
public static void main(String[] args) {
Accounts squareRoot = new Accounts() {
@Override
public boolean showAccountType(String accountType) {
if ("Savings" == accountType)
return true;
else
return false;
}
};
if (squareRoot.showAccountType("Savings"))
System.out.println("Savings");
else
System.out.println("Invalid Account");
}
}
|
| Function |
Accounts.java
@FunctionalInterface
public interface Accounts
{
abstract String showAccountType(String accountType, String returnAccType);
}
AccountImpl.java
public class AccountImpl {
public static void main(String[] args) {
//Implementation of Custom Function Method for Accounts Interface
Accounts squareRoot = (accountType, returnType) -> {
if (accountType == "Savings")
return "Credit";
else
return "Debit";
};
System.out.println(squareRoot.showAccountType("Savings", null));
}
}
The above code could be expanded as below using Anonymous Inner Class
public class AccountImpl {
public static void main(String[] args) {
Accounts squareRoot = new Accounts() {
@Override
public String showAccountType(String accountType, String returnAccType) {
if (accountType == "Savings")
return "Credit";
else
return "Debit";
}
};
System.out.println(squareRoot.showAccountType("Savings", null));
}
}
|
| Urnary Operator |
Accounts.java
@FunctionalInterface
public interface Accounts{
abstract String showAccountType(String accountType);
}
AccountImpl.java
public class AccountImpl {
public static void main(String[] args) {
//Implementation of Custom Operator Method for Accounts Interface
Accounts squareRoot = (accountType) -> {
return "AccountType is " + accountType;
};
squareRoot.showAccountType("Savings");
}
}
The above code could be expanded as below using Anonymous Inner Class
public class AccountImpl {
public static void main(String[] args) {
Accounts squareRoot = new Accounts() {
@Override
public String showAccountType(String accountType) {
return "AccountType is " + accountType;
}
};
System.out.println(squareRoot.showAccountType("Savings"));
}
}
|
Category Archives: Java 8
What is Optional in Java 8
- Optional is a wrapper class which makes a field optional which means it may or may not have values.
- ptional as a single-value container that either contains a value or doesn’t (it is then said to be “empty”)
- The advantage compared to null references is that the Optional class forces you to think about the case when the value is not present. As a consequence, you can prevent unintended null pointer exceptions.
- The intention of the Optional class is not to replace every single null reference. Instead, its purpose is to help design more-comprehensible APIs so that by just reading the signature of a method, you can tell whether you can expect an optional value. This forces you to actively unwrap an Optional to deal with the absence of a value.
Lets take the below code
String version = computer.getSoundcard().getUSB().getVersion();
In the above piece of java code if any of the 3 values other the Version is NULL will throw a null pointer exception. To prevent this lets add a null check
String version = "UNKNOWN";
if(computer != null){
Soundcard soundcard = computer.getSoundcard();
if(soundcard != null){
USB usb = soundcard.getUSB();
if(usb != null){
version = usb.getVersion();
}
}
}
Now the above code has become Clumsy with less readability and lot of boilerplate code has been added.
In languages like Groovy these conditions could be handles like one below
String version = computer?.getSoundcard()?.getUSB()?.getVersion();
(or)
String version =
computer?.getSoundcard()?.getUSB()?.getVersion() ?: "UNKNOWN";
Now lets replace the above code with new Optional in Java 8
public class Computer {
private Optional<Soundcard> soundcard;
public Optional<Soundcard> getSoundcard() { ... }
...
}
public class Soundcard {
private Optional<USB> usb;
public Optional<USB> getUSB() { ... }
}
public class USB{
public String getVersion(){ ... }
}
The advantage compared to null references is that the Optional class forces you to think about the case when the value is not present. As a consequence, you can prevent unintended null pointer exceptions.
What is the Point of Optional when the same could be done using NULL Check?
If you are doing NULL check the traditional way there would be no much difference. However, the difference is felt when you are carrying out chaining operations in streams and the datatypes returned are optional.The difference may not be significant in this case but as the chain of objects increases e.g. person.getAddress.getCity().getStreet().getBlock(),
Methods in Optional
get()
If a value is present in this Optional, returns the value, otherwise throws NoSuchElementException
void ifPresent(Consumer consumer)
If a value is present, it invokes the specified consumer with the value, otherwise does nothing.
boolean isPresent()
Returns true if there is a value present, otherwise false.
static
Returns an Optional describing the specified value, if non-null, otherwise returns an empty Optional.
T orElse(T other)
Returns the value if present, otherwise returns other.
T orElseGet(Supplier other)
Returns the value if present, otherwise invokes other and returns the result of that invocation.
orElseThrow(Supplier exceptionSupplier)
Returns the contained value, if present, otherwise throws an exception to be created by the provided supplier.
Lets take a simple example where Optional returns Empty or Value based on some Condition
package com.example.demo;
import java.util.Optional;
public class Test {
public static void main(String[] args) {
//IfPresent
Optional < String > strOpt = getName(" Piggy");
System.out.print("First Call -");
strOpt.ifPresent(System.out::println);
Optional < String > strOpt2 = getName("");
System.out.print("Second Call -");
strOpt2.ifPresent(System.out::println);
System.out.println();
//IsPresent and get
Optional < String > strOpt3 = getNewName(" Biggy");
System.out.print("Third Call -");
if (strOpt3.isPresent())
System.out.println(strOpt3.get());
//orElse
Optional < String > strOpt4 = getNewName(null);
System.out.print("Fourth Call -");
System.out.println(strOpt4.orElse(" Hippi"));
}
public static Optional < String > getName(String strName) {
if (strName.length() > 0)
return Optional.of(strName);
else
return Optional.empty();
}
public static Optional < String > getNewName(String strName) {
//Optional strNewName = (strName!=null)?Optional.of(strName):Optional.empty();
return Optional.ofNullable(strName);
}
}
Output
First Call - Piggy Second Call - Third Call - Biggy Fourth Call - Hippi
Method References in Java
Method reference is used to refer method of functional interface. It is compact and easy form of lambda expression. Each time when you are using lambda expression to just referring a method, you can replace your lambda expression with method reference.
3 types of method references:
- Reference to a static method
- Reference to an instance method
- Reference to a constructor
Reference to a static method
Syntax
ClassName::MethodName
import java.util.function.BiFunction;
class Arithmetic
{
public static int add(int a, int b)
{
return a + b;
}
}
public class MethodReference
{
public static void main(String[] args)
{
BiFunction < Integer, Integer, Integer > adder = Arithmetic::add;
int result = adder.apply(10, 20);
System.out.println(result);
}
}
Reference to an instance method
Syntax
Object::methodName
import java.util.function.BiFunction;
class Arithmetic
{
public int add(int a, int b)
{
return a + b;
}
}
public class MethodReference
{
public static void main(String[] args)
{
Arithmetic objArithmetic = new Arithmetic();
BiFunction < Integer, Integer, Integer > adder = objArithmetic::add;
int result = adder.apply(10, 20);
System.out.println(result);
}
}
Reference to a constructor
Syntax
ClassName::new
interface Messageable {
Message getMessage(String msg);
}
class Message {
Message(String msg) {
System.out.print(msg);
}
}
public class ConstructorReference {
public static void main(String[] args) {
Messageable hello = Message::new;
hello.getMessage("Hello");
}
}
Why, What and How – Java Streams
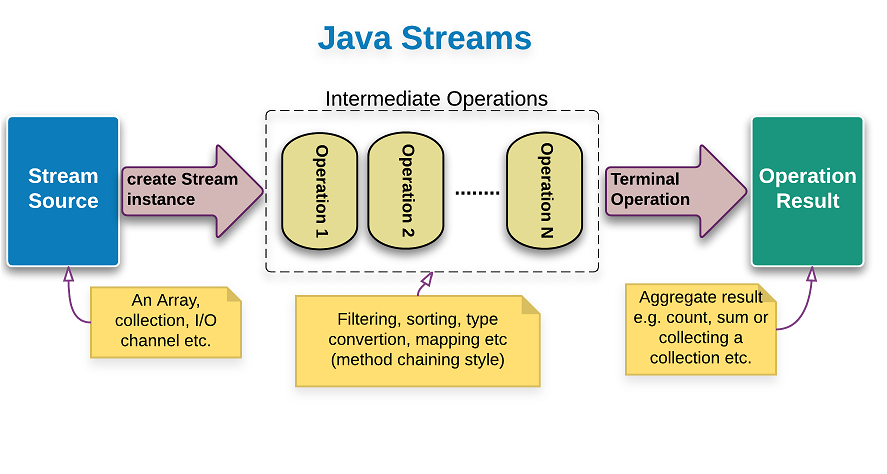
Stream is a sequence of data that you can process in a declarative and functional style. The Stream interface is located in the java.util.stream package. It represents a sequence of objects somewhat like the Iterator interface. However, unlike the Iterator, it supports parallel execution.The Stream interface supports the map/filter/reduce pattern and executes lazily, forming the basis (along with lambdas) for functional-style programming in Java 8.
There are also corresponding primitive streams (IntStream, DoubleStream, and LongStream) for performance reasons. Let’s take a simple example of Iterating through a List with aim of summing up numbers above 10. This laziness is achieved by a separation between two types of operations that could be executed on streams: intermediate and terminal operations.
private static int sumIterator(List<Integer> list) {
Iterator<Integer> it = list.iterator();
int sum = 0;
while (it.hasNext()) {
int num = it.next();
if (num > 10) {
sum += num;
}
}
return sum;
}
The Disadvantages of above method are
- The program is sequential in nature, there is no way we can do this in parallel easily.
- We need to provide the code logic for sum of integers on how the iteration will take place, this is also called external iteration because client program is handling the algorithm to iterate over the list.
To overcome the above issue Java 8 introduced Java Stream API to implement internal iteration, that is better because java framework is in control of the iteration.Internal iteration provides several features such as sequential and parallel execution, filtering based on the given criteria, mapping etc.Java 8 Stream API method arguments are functional interfaces, so lambda expressions work very well with them. Using Stream the same code turnout to be
private static int sumStream(List<Integer> list) {
return list.stream().filter(i -> i > 10).mapToInt(i -> i).sum();
}
Streams are lazy because intermediate operations are not evaluated unless a terminal operation is invoked. Each intermediate operation creates a new stream, stores the provided operation/function and return the new stream. The pipeline accumulates these newly created streams.The time when terminal operation is called, traversal of streams begins and the associated function is performed one by one. Parallel streams don’t evaluate streams ‘one by one’ (at the terminal point). The operations are rather performed simultaneously, depending on the available cores.
To perform a sequence of operations over the elements of the data source and aggregate their results, three parts are needed –
- Source
- intermediate operation
- terminal operation
How to create a simple stream
Collection<String> collection = Arrays.asList("a", "b", "c");
Stream<String> streamOfCollection = collection.stream();
Stream<String> streamOfArray = Stream.of("a", "b", "c");
String[] arr = new String[]{"a", "b", "c"};
Stream<String> streamOfArrayFull = Arrays.stream(arr);
Stream<String> streamOfArrayPart = Arrays.stream(arr, 1, 3);
Using Stream.builder() When builder is used the desired type should be additionally specified in the right part of the statement, otherwise the build() method will create an instance of the Stream Object
Stream<String> streamBuilder =
Stream.<String>builder().add("a").add("b").add("c").build();
Using Stream.generate()
The generate() method accepts a Supplier
Stream<String> streamGenerated = Stream.generate(() -> "element").limit(10);
The code above creates a sequence of ten strings with the value – “element”.
Stream.iterate()
Another way of creating an infinite stream is by using the iterate() method:
Stream<Integer> streamIterated = Stream.iterate(40, n -> n + 2).limit(20);
The first element of the resulting stream is a first parameter of the iterate() method. For creating every following element the specified function is applied to the previous element. In the example above the second element will be 42.
A stream by itself is worthless, the real thing a user is interested in is a result of the terminal operation, which can be a value of some type or action applied to every element of the stream. Only one terminal operation can be used per stream.
For More details on streams refer here
How to implement Synchronized ArrayList in Java
ArrayList is not synchronized. That means sharing an instance of ArrayList among many threads where those threads are modifying (by adding or removing the values) the collection may result in unpredictable behavior.A thread-safe variant of ArrayList in which all mutative operations (e.g. add, set, remove..) are implemented by creating a separate copy of underlying array. It achieves thread-safety by creating a separate copy of List which is a is different way than vector or other collections use to provide thread-safety.Iterator does not throw ConcurrentModificationException even if copyOnWriteArrayList is modified once iterator is created because iterator is iterating over the separate copy of ArrayList while write operation is happening on another copy of ArrayList.
There are two ways to Synchronize ArrayList
- Collections.synchronizedList() method – It returns synchronized list backed by the specified list.
- CopyOnWriteArrayList class – It is a thread-safe variant of ArrayList.
Collections.synchronizedList()
import java.util.*;
class GFG
{
public static void main (String[] args)
{
List<String> list =
Collections.synchronizedList(new ArrayList<String>());
list.add("practice");
list.add("code");
list.add("quiz");
synchronized(list)
{
// must be in synchronized block
Iterator it = list.iterator();
while (it.hasNext())
System.out.println(it.next());
}
}
}
CopyOnWriteArrayList
import java.io.*;
import java.util.Iterator;
import java.util.concurrent.CopyOnWriteArrayList;
class GFG
{
public static void main (String[] args)
{
// creating a thread-safe Arraylist.
CopyOnWriteArrayList<String> threadSafeList
= new CopyOnWriteArrayList<String>();
// Adding elements to synchronized ArrayList
threadSafeList.add("geek");
threadSafeList.add("code");
threadSafeList.add("practice");
System.out.println("Elements of synchronized ArrayList :");
// Iterating on the synchronized ArrayList using iterator.
Iterator<String> it = threadSafeList.iterator();
while (it.hasNext())
System.out.println(it.next());
}
}
Java 8 Interview Questions
1.What is the Default Size and Capacity of ArrayList in Java 8?What is the Maximum Size of ArrayList?
Size is the number of elements you have placed into the arrayList while capacity is the max number of elements the arrayList can take. Once you’ve reached max, the capacity is doubled.The initial List size is zero (unless you specify otherwise).However the initial capacity of ArrayList is 10.The size of the list is the number of elements in it. The capacity of the list is the number of elements the backing data structure can hold at this time. The size will change as elements are added to or removed from the list. The capacity will change when the implementation of the list you’re using needs it to. (The size, of course, will never be bigger than the capacity.)
When it has to grow, this is used:
int newCapacity = oldCapacity + (oldCapacity >> 1)
oldCapacity >> 1 is division by two, so it grows by 1.5
int newCapacity = oldCapacity + (oldCapacity >> 1); int newCapacity = oldCapacity + 0.5*oldCapacity; int newCapacity = 1.5*oldCapacity ;
Maximum Size of ArrayList
It would depend on the implementation, but the limit is not defined by the List interface.An ArrayList can’t hold more than Integer.MAX_VALUE elements
2.Difference is between a fixed size container (data structure) and a variable size container.
An array is a fixed size container, the number of elements it holds is established when the array is created and never changes. (When the array is created all of those elements will have some default value, e.g., null for reference types or 0 for ints, but they’ll all be there in the array: you can index each and every one.)
A list is a variable size container, the number of elements in it can change, ranging from 0 to as many as you want (subject to implementation limits). After creation the number of elements can either grow or shrink. At all times you can retrieve any element by its index.
List is actually an interface and it can be implemented in many different ways. Thus, ArrayList, LinkedList, etc. There is a data structure “behind” the list to actually hold the elements. And that data structure itself might be fixed size or variable size, and at any given time might have the exact size of the number of elements in the list, or it might have some extra “buffer” space.The LinkedList, for example, always has in its underlying data structure exactly the same number of “places for elements” as are in the list it is representing. But the ArrayList uses a fixed length array as its backing store.
3.How to create a Synchronized ArrayList
There are two ways to Synchronize ArrayList
- Collections.synchronizedList() method – It returns synchronized list backed by the specified list.
- CopyOnWriteArrayList class – It is a thread-safe variant of ArrayList.It achieves thread-safety by creating a separate copy of List which is a is different way than vector or other collections use to provide thread-safety
More here
4.Why to use arrayList when vector is synchronized?
Vector synchronizes at the level of each individual operation. Generally a programmer like to synchronize a whole sequence of operations. Synchronizing individual operations is both less safe and slower.Vectors are considered obsolete an d unofficially deprecated in java.
5.Difference between CopyOnWriteArrayList and synchronizedList
Both synchronizedList and CopyOnWriteArrayList take a lock on the entire array during write operations.The difference emerges if you look at other operations, such as iterating over every element of the collection. The documentation for Collections.synchronizedList says It is imperative that the user manually synchronize on the returned list when iterating over it.Failure to follow this advice may result in non-deterministic behavior.
List list = Collections.synchronizedList(new ArrayList());
...
synchronized (list) {
Iterator i = list.iterator(); // Must be in synchronized block
while (i.hasNext())
foo(i.next());
}
Iterating over a synchronizedList is not thread-safe unless you do locking manually. Note that when using this technique, all operations by other threads on this list, including iterations, gets, sets, adds, and removals, are blocked. Only one thread at a time can do anything with this collection.
CopyOnWriteArrayList uses “snapshot” style iterator method uses a reference to the state of the array at the point that the iterator was created. This array never changes during the lifetime of the iterator, so interference is impossible and the iterator is guaranteed not to throw ConcurrentModificationException. The iterator will not reflect additions, removals, or changes to the list since the iterator was created. “snapshot” style iterator method uses a reference to the state of the array at the point that the iterator was created. This array never changes during the lifetime of the iterator, so interference is impossible and the iterator is guaranteed not to throw ConcurrentModificationException. The iterator will not reflect additions, removals, or changes to the list since the iterator was created.
Operations by other threads on this list can proceed concurrently, but the iteration isn’t affected by changes made by any other threads. So, even though write operations lock the entire list, CopyOnWriteArrayList still can provide higher throughput than an ordinary synchronizedList.
6.What is Functional Interface?What are the rules to define a Functional Interface?Is it Mandatory to define @FunctionalInterface annotation?
Functional Interface also know as Single Abstract Method(SAM) interface contains one and only one abstract method. @FunctionalInterface is not amndatory but tells other developers the interface is Functional and prevents them from adding anymore methods to it.We can have any number of Default methods and Static methods.Overridding methods in java.lang.object such as equals and hashcode doesnot count as an abstract method. More here
7.Difference between Streams and Collections?
| Stream | Collections |
|---|---|
| A stream is not a data structure that stores elements; instead, it conveys elements from a source such as a data structure, an array, a generator function, or an I/O channel, through a pipeline of computational operations. | Collection is a Datastructure |
| An operation on a stream produces a result, but does not modify its source. For example, filtering a Stream obtained from a collection produces a new Stream without the filtered elements, rather than removing elements from the source collection. | Operation on collection will have direct impact on collection object itself |
| Streams are based on ‘process-only, on-demand’ strategy.Many stream operations, such as filtering, mapping, or duplicate removal, can be implemented lazily, exposing opportunities for optimization. Stream operations are divided into intermediate (Stream-producing) operations and terminal (value- or side-effect-producing) operations. Intermediate operations are always lazy. | All Data Values in collections are processed in single shot |
| Stream acts upon infinite set of Values i.e. infinite stream | Collections always act upon finite set of Data |
| The elements of a stream are only visited once during the life of a stream. Like an Iterator, a new stream must be generated to revisit the same elements of the source. | Collections can be iterated any number of Times |
8.How do I read / convert an InputStream into a String in Java?
Using Apache commons IOUtils to copy the InputStream into a StringWriter
StringWriter writer = new StringWriter(); IOUtils.copy(inputStream, writer, encoding); String theString = writer.toString();
String theString = IOUtils.toString(inputStream, encoding);
Using only the standard Java library
static String convertStreamToString(java.io.InputStream is) {
java.util.Scanner s = new java.util.Scanner(is).useDelimiter("\\A");
return s.hasNext() ? s.next() : "";
}
Scanner iterates over tokens in the stream, and in this case we separate tokens using “beginning of the input boundary” (\A), thus giving us only one token for the entire contents of the stream.
9.How do I convert a String to an InputStream in Java?
InputStream stream = new ByteArrayInputStream(exampleString.getBytes(StandardCharsets.UTF_8));
Using Apache Commons IO
String source = "This is the source of my input stream"; InputStream in = org.apache.commons.io.IOUtils.toInputStream(source, "UTF-8");
Using StringReader
String charset = ...; // your charset byte[] bytes = string.getBytes(charset); ByteArrayInputStream bais = new ByteArrayInputStream(bytes); InputStreamReader isr = new InputStreamReader(bais);
10.Difference between hashtable and hashmap?
Click here
11.What is exception-masking?
When code in a try block throws an exception, and the close method in the finally also throws an exception, the exception thrown by the try block gets lost and the exception thrown in the finally gets propagated. This is usually unfortunate, since the exception thrown on close is something unhelpful while the useful exception is the informative one. Using try-with-resources to close your resources will prevent any exception-masking from taking place.
11.Try With Resources vs Try-Catch
- The main point of try-with-resources is to make sure resources are closed, without requiring the application code to do it.
- when there are situations where two independent exceptions can be thrown in sibling code blocks, in particular in the try block of a try-with-resources statement and the compiler-generated finally block which closes the resource. In these situations, only one of the thrown exceptions can be propagated. In the try-with-resources statement, when there are two such exceptions, the exception originating from the try block is propagated and the exception from the finally block is added to the list of exceptions suppressed by the exception from the try block. As an exception unwinds the stack, it can accumulate multiple suppressed exceptions.
- On the other hand if your code completes normally but the resource you’re using throws an exception on close, that exception (which would get suppressed if the code in the try block threw anything) gets thrown. That means that if you have some JDBC code where a ResultSet or PreparedStatement is closed by try-with-resources, an exception resulting from some infrastructure glitch when a JDBC object gets closed can be thrown and can rollback an operation that otherwise would have completed successfully.
12.How to get Suppressed Exceptions?
only one exception can be thrown by a method (per execution) but it is possible, in the case of a try-with-resources, for multiple exceptions to be thrown. For instance one might be thrown in the block and another might be thrown from the implicit finally provided by the try-with-resources.The compiler has to determine which of these to “really” throw. It chooses to throw the exception raised in the explicit code (the code in the try block) rather than the one thrown by the implicit code (the finally block). Therefore the exception(s) thrown in the implicit block are suppressed (ignored). This only occurs in the case of multiple exceptions.
The try-catch-resource block does expose the suppressed exception using the new (since Java 1.7) getSuppressed() method. This method returns all of the suppressed exceptions by the try-catch-resource block (notice that it returns ALL of the suppressed exceptions if more than one occurred). A caller might use the following structure to reconcile with existing behavior
try {
testJava7TryCatchWithExceptionOnFinally(); //Method throws exception in both try and finally block
} catch (IOException e) {
Throwable[] suppressed = e.getSuppressed();
for (Throwable t : suppressed) {
// Check T's type and decide on action to be taken
}
}
13.How do you avoid fuzzy try-catch blocks in code like one below?
try{
...
stmts
...
}
catch(Exception ex) {
...
stmts
...
} finally {
connection.close // throws an exception
}
Write a SQLUtils class that contains static closeQuietly methods that catch and log such exceptions, then use as appropriate.
public class SQLUtils
{
private static Log log = LogFactory.getLog(SQLUtils.class);
public static void closeQuietly(Connection connection)
{
try
{
if (connection != null)
{
connection.close();
}
}
catch (SQLExcetpion e)
{
log.error("An error occurred closing connection.", e);
}
}
public static void closeQuietly(Statement statement)
{
try
{
if (statement!= null)
{
statement.close();
}
}
catch (SQLExcetpion e)
{
log.error("An error occurred closing statement.", e);
}
}
public static void closeQuietly(ResultSet resultSet)
{
try
{
if (resultSet!= null)
{
resultSet.close();
}
}
catch (SQLExcetpion e)
{
log.error("An error occurred closing result set.", e);
}
}
}
and
Connection connection = null;
Statement statement = null;
ResultSet resultSet = null;
try
{
connection = getConnection();
statement = connection.prepareStatement(...);
resultSet = statement.executeQuery();
...
}
finally
{
SQLUtils.closeQuietly(resultSet);
SQLUtils.closeQuietly(statment);
SQLUtils.closeQuietly(connection);
}
14.What is Difference between Iterator and Split Iterator
A Spliterator can be used to split given element set into multiple sets so that we can perform some kind of operations/calculations on each set in different threads independently, possibly taking advantage of parallelism. It is designed as a parallel analogue of Iterator. Other than collections, the source of elements covered by a Spliterator could be, for example, an array, an IO channel, or a generator function.
There are 2 main methods in the Spliterator interface.
- tryAdvance()- With tryAdvance(), we can traverse underlying elements one by one (just like Iterator.next()). If a remaining element exists, this method performs the consumer action on it, returning true; else returns false.
- forEachRemaining() -For sequential bulk traversal we can use forEachRemaining()
A Spliterator is also a “smarter” Iterator, via it’s internal properties like DISTINCT or SORTED, etc (which you need to provide correctly when implementing your own Spliterator). These flags are used internally to disable unnecessary operations, also called optimizations, like this one for example:
someStream().map(x -> y).count();
Because size does not change in case of the stream, the map can be skipped entirely, since all we do is counting.
You can create a Spliterator around an Iterator if you would need to, via:
Spliterators.spliteratorUnknownSize(yourIterator, properties)
15.What is Type Inference?
Type Inference means determining the Type by compiler at compile-time.It is not new feature in Java SE 8. It is available in Java 7 and before Java 7 too.Java 8 uses Type inference for calling lambda expressions. Refer here
16.What is Optional in Java 8? What is the use of Optional?Advantages of Java 8 Optional?
Optional is a final Class introduced as part of Java SE 8. It is defined in java.util package.It is used to represent optional values that is either exist or not exist. It can contain either one value or zero value. If it contains a value, we can get it. Otherwise, we get nothing.It is a bounded collection that is it contains at most one element only. It is an alternative to “null” value.
17.What is difference between initialization and instantiation?
instantiation – This is when memory is allocated for an object. This is what the new keyword is doing. A reference to the object that was created is returned from the new keyword.
initialization – This is when values are put into the memory that was allocated. This is what the Constructor of a class does when using the new keyword.A variable must also be initialized by having the reference to some object in memory passed to it.
Refer here
18.What are different Method References in Java?
- Reference to a static method – ClassName::MethodName
- Reference to an instance method – Object::methodName
- Reference to a constructor – ClassName::new
Refer Here
19.What are the difference between predicate and function?
Predicate interface has an abstract method test(T t) which has a Boolean return type. Usage, when we need to return/check the condition as True or False. It is best suited to code.
Function interface has an abstract method apply which takes the argument of type T and returns a result of type R. Here, R is nothing but the type of result user wants to return. It may be Integer, String, Boolean, Double, Long.
20.Why to go for Optional instead of NULL Check?
The Effectiveness of Optional could be only seen during Chaining in Streams or when accessing multiple getters at once like one below
.
.
computer.getSoundcard().getUSB().getVersion();
.
.
.
Optional.ofNullable(modem2)
.map(Modem::getPrice)
.filter(p -> p >= 10)
.filter(p -> p <= 15)
.isPresent();
21.What is Lambda Expressions?
The Lambda expression is used to provide the implementation for abstract method in functional interface. No need to define the method again for providing the implementation. Here, we just write the implementation code.
@FunctionalInterfac
interface Drawable {
public void draw();
}
public class LambdaExpressionExample2 {
public static void main(String[] args) {
int width = 10;
//with lambda
Drawable d2 = () -> {
System.out.println("Drawing " + width);
};
d2.draw();
}
}
22.How to handle Checked Exceptions in Lambda Expressions?
To handle checked exception we use a lambda wrapper for the lambda function. Refer here
23.What is the Difference between Lambda Expression and Anonymous Inner Class?
The key difference between Anonymous class and Lambda expression is the usage of ‘this’ keyword. In the anonymous classes, ‘this’ keyword resolves to anonymous class itself, whereas for lambda expression ‘this’ keyword resolves to enclosing class where lambda expression is written.
Another difference between lambda expression and anonymous class is in the way these two are compiled. Java compiler compiles lambda expressions and convert them into private method of the class. It uses invokedynamic instruction that was added in Java 7 to bind this method dynamically.
Functions reside in permanent memory whereas for classes the memory is loaded on demand.
Functions act on unrelated data whereas objects act on their own data.
Refer here
24.Why static methods are Not allowed in Interface prior to Java 8?
Prior to Java 8 Interface could only have abstract methods. If you are writing a static method and defining it then the defining of the static methods may vary based on the implementing classes. So if two classes implement static method and since the
purpose of interface is to provide multiple inheritance when the fourth class implementsthe second and third method which is overrided the it would lead to Diamond of Death Problem.
This is similar to same thing with default methods in Java 8
This Works
class Animal {
public static void identify() {
System.out.println("This is an animal");
}
}
class Cat extends Animal {}
public static void main(String[] args) {
Animal.identify();
Cat.identify(); // This compiles, even though it is not redefined in Cat.
}
This Doesnot Works
interface Animal {
public static void identify() {
System.out.println("This is an animal");
}
}
class Cat implements Animal {}
public static void main(String[] args) {
Animal.identify();
Cat.identify(); // This does not compile, because interface static methods do not inherit. (Why?)
}
Cat can only extend one class so if Cat extends Animal, Cat.identify has only one meaning. Cat can implement multiple interfaces each of which can have a static implementation.
So Java Compiler is not sure which implementation to call
25.Explain different memory Allocation in JVM?
Memory in Java is divided into two portions
Stack: One stack is created per thread and it stores stack frames which again stores local variables and if a variable is a reference type then that variable refers to a memory location in heap for the actual object.
Heap: All kinds of objects will be created in heap only.
Heap memory is again divided into 3 portions
Young Generation: Stores objects which have a short life, Young Generation itself can be divided into two categories Eden Space and Survivor Space.
Old Generation: Store objects which have survived many garbage collection cycles and still being referenced.
Permanent Generation: Stores metadata about the program e.g. runtime constant pool.
What,Why and When Lambda Expression
Why Lambda Expressions
Now Lets Iterate through the simple ArrayList
Without Lambda Expressions
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6);
for (int number : numbers)
{
System.out.println(number);
}
We iterate the collection externally, explicitly pulling out and processing the items one by one. Now through Lambda Expressions, we are using an internal iteration the JIT compiler could optimize it processing the items in parallel or in a different order. These optimizations are impossible if we iterate the collection externally as we are used to doing in Java and more in general with the imperative programming.
With Lambda Expressions
numbers.forEach((Integer value) -> System.out.println(value)); (or) numbers.forEach(value -> System.out.println(value));
Apart from the above reason Lambdas allows us to
- Enable to treat functionality as a method argument, or code as data.
- A function that can be created without belonging to any class.
- A lambda expression can be passed around as if it was an object and executed on demand.
- It reduces the line of code.
- It Supports Sequential and Parallel execution by passing behavior in methods with collection stream API
- Using Stream API and lambda expression we can achieve higher efficiency (parallel execution) in the case of bulk operations on collections
Java 8 Lambda uses JVM Opcode – invokedynamic
The Following code will result in Anonymous class being created when you compile the code.
So if you have 10 anonymous classes then it would be 10 more classes like(ClassName$1.class,ClassName$2.class….ClassName$10.class) in the final jar.
AccountService accountServiceAnonymous = new AccountService(){
public void createAccount(){
Account account = new Account();
save(account);
}
};
But Java 8 lambda uses invokedynamic to call lambdas thus if you have 10 lambdas it will not result in any anonymous classes thus reducing the final jar size.
AccountService accountServiceLambda = () -> {
Account account = new Account();
save(account);
}
What are Functional Interface? How it works?
Functional interfaces have a single functionality to exhibit. For example, a Comparable interface with a single method compareTo is used for comparison purpose
Functional Interface is an interface which has one and only one abstract method. Apart from abstract method, it can have any number of default and static methods which have an implementation and are not abstract and overridden method from Object.These interfaces are also called Single Abstract Method Interfaces. Few Functional Interfaces are Comparable, Runnable and etc.
Example of Functional Interface
@FunctionalInterface
public interface MyFunctionalInterface
{
public void MethodOne(int i, double d);
}
@FunctionalInterface
public interface MyFunctionalInterface
{
public void MethodOne(int i, double d);
default boolean methodTwo(String value)
{
return true;
}
}
@FunctionalInterface annotation is used to mark an interface as Functional Interface
not mandatory to use it. If the interface is annotated with @FunctionalInterface annotation and when we
try to have more than one abstract method, it throws the compiler error.
There are two ways the abstract method definition in the functional interface could be done
One is by Anonymous Inner class and other is by Lambda Expression
For example in Java, if we have to instantiate runnable interface anonymously, then our code looks like below. It’s bulky
Anonymous Inner class way of method definion for Functional Interface
Runnable r = new Runnable(){
@Override
public void run()
{
System.out.println("My Runnable");
}};
lambda expressions for the above method implementation is
Lambda Expressions way of method definion for Functional Interface
Runnable r1 = () -> {
System.out.println("My Runnable");
};
Functional interface with abstract method(oneMethod) and default(getMulty), static methods(getSum) which have an implementation and are not abstract and methods overridden from Object Class(toString and equals).
@FunctionalInterface
public interface MyFunctionalInterface
{
public void oneMethod(int i, double d);
public String toString();
public boolean equals(Object o);
public static int getSum(int a,int b)
{// valid->method static
return a+b;
}
public default int getMulty(int c,int d)
{//valid->method default
return c+d;
}
}
Functional Interface could be classified into the following 5 Types based on the parameters and the way the abstract method behaves
- Supplier
- Consumer
- Predicate
- Function
- Operator
| Functional Interface | Parameter Types | Return Type | Abstract Method Name | Description |
|---|---|---|---|---|
| Runnable | none | void | run | Runs an action without arguments or return value |
| Supplier |
none | T | get | Supplies a value of type T |
| Consumer |
T | void | accept | Consumes a value of type T |
| BiConsumer |
T, U | void | accept | Consumes values of types T and U |
| Function |
T | R | apply | A function with argument of type T |
| BiFunction |
T, U | R | apply | A function with arguments of types T and U |
| UnaryOperator |
T | T | apply | A unary operator on the type T |
| BinaryOperator |
T, T | T | apply | A binary operator on the type T |
| Predicate |
T | boolean | test | A Boolean-valued function |
| BiPredicate |
T, U | boolean | test | A Boolean-valued function with two arguments |
What is need for Default Method in Functional Interface?
- If we want to add additional methods in the interfaces, it will require change in all the implementing classes.
- As interface grows old, the number of classes implementing it might grow to an extent that its not possible to extend interfaces.
- That’s why when designing an application, most of the frameworks provide a base implementation class and then we extend it and override methods that are applicable for our application.
- “Default Method” or Virtual extension methods or Defender methods feature, which allows the developer to add new methods to the interfaces without breaking their existing implementation. It provides the flexibility to allow interface to define implementation which will use as the default in a situation where a concrete class fails to provide an implementation for that method.
Lets Imagine we have UserDevices which later wants to provide support for blackberry devices at later part of Software release. You cannot have a abstract method for blackberrySupport and make the implementing classes to do method definition.Instead of that I am writing as default method in interface which prevents all the implementing classes to write its own method definition.
public interface UserDevices {
default void blackberrySupport(){
System.out.println("Support for Blackberry Devices");
}
}
public class Device implements UserDevices {
}
What if the class implements two interfaces and both those interfaces define a default method with the same signature?
public interface UserDevices1 {
default void blackberrySupport(){
System.out.println("Support for Blackberry Devices1");
}
}
public interface UserDevices2 {
default void blackberrySupport(){
System.out.println("Support for Blackberry Devices2");
}
}
public class Device implements UserDevices1 , UserDevices2 {
}
This code fails to compile with the following result:
java: class Device inherits unrelated defaults for blackberrySupport() from types UserDevices1 and UserDevices2
In this case we have to resolve it manually by overriding the conflicting method
public class Device implements UserDevices1, UserDevices2 {
public void blackberrySupport(){
UserDevices1.super.blackberrySupport();
}
}
The Best Example of Default Method is addition of foreach method in java.util.List Interface.