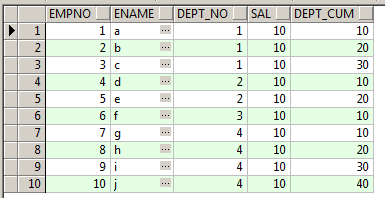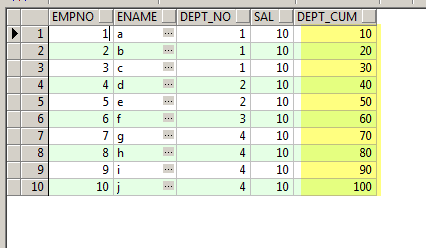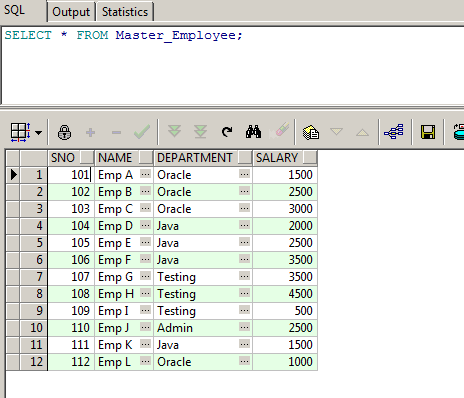
SELECT Sno,
Name,
Department,
Salary,
SUM(Salary) over(PARTITION BY Department ORDER BY Sno) AS Cum_Salary
FROM Master_Employee
ORDER BY Department;
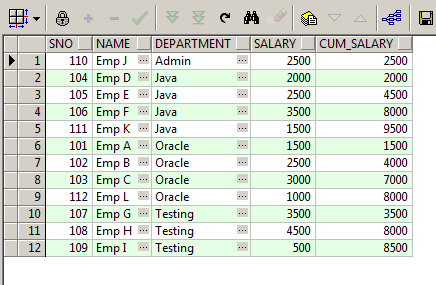
How this Works
PARTITION BY Department ORDER BY Sno
Partition By will first Partition by Department.Which means the Cumulative Sum will get Reset once the Department Changes.
ORDER BY Sno will make sure the Cumulative value calculated will not be swapped and stays the same for the respective rows.
Now to have a total amount for the Salary the query is as below.
SELECT Sno,
Name,
Department,
Salary
FROM Master_Employee
UNION
SELECT null,
null,
'Total',
NVL(SUM(Salary), 0)
FROM Master_Employee
ORDER BY Sno;
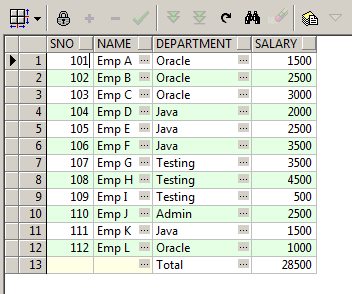
Total along with Cumulative Sum
SELECT Sno,
Name,
Department,
Salary,
SUM(Salary) over(PARTITION BY Department ORDER BY Sno) AS Cum_Salary
FROM Master_Employee
UNION
SELECT null,
null,
'Total',
NVL(SUM(Salary), 0),
null
FROM Master_Employee
ORDER BY Sno;
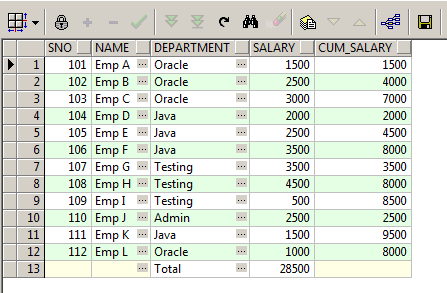
Another wat of fetching records using sub query
SELECT Sno,
Name,
Department,
Salary,
CASE
WHEN Department = 'Total' THEN
NULL
ELSE
SUM(Salary) over(PARTITION BY Department ORDER BY Sno)
END AS Cum_Salary
FROM (SELECT Sno, Name, Department, Salary, null, 1 AS Sort_Order
FROM Master_Employee
UNION
SELECT null,
null,
'Total',
NVL(SUM(Salary), 0),
null,
2 AS Sort_Order
FROM Master_Employee)
ORDER BY Department, Sno, Sort_Order;