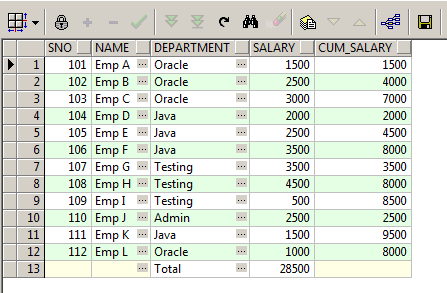
VLOOKUP lets you search for specific information in your spreadsheet
Adding the arguments
Now, we’ll add our arguments. The arguments will tell VLOOKUP what to search for and where to search.
The first argument is the name of the item you’re searching for, which in this case is Photo frame. Because the argument is text, we’ll need to put it in double quotes:
=VLOOKUP(“Item 5”
The second argument is the cell range that contains the data. In this example, our data is in A2:B16. As with any function, you’ll need to use a comma to separate each argument:
=VLOOKUP(“Item 5”, A2:B16
Note: It’s important to know that VLOOKUP will always search the first column in this range. In this example, it will search column A for “Item 5”. In some cases, you may need to move the columns around so the first column contains the correct data.
The third argument is the column index number. It’s simpler than it sounds: The first column in the range is 1, the second column is 2, etc. In this case, we are trying to find the price of the item, and the prices are contained in the second column. This means our third argument will be 2:
=VLOOKUP(“Item 5”, A2:B16, 2
The fourth argument tells VLOOKUP whether to look for approximate matches, and it can be either TRUE or FALSE. If it is TRUE, it will look for approximate matches. Generally, this is only useful if the first column has numerical values that have been sorted. Because we’re only looking for exact matches, the fourth argument should be FALSE. This is our last argument, so go ahead and close the parentheses:
=VLOOKUP(“Item 5”, A2:B16, 2, FALSE)
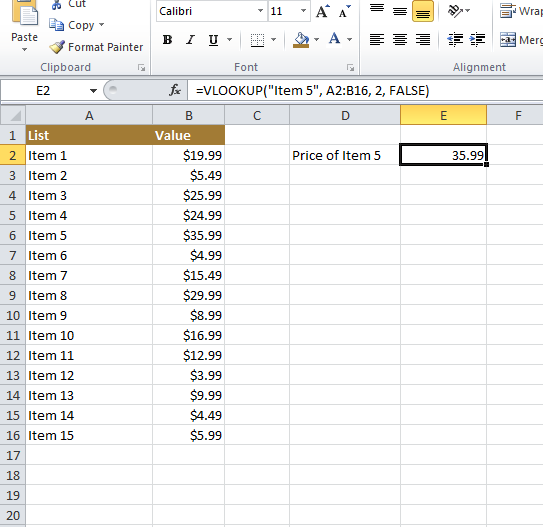
Finding Value of Particular Data
=VLOOKUP("Item 5", A2:B16, 2, FALSE)
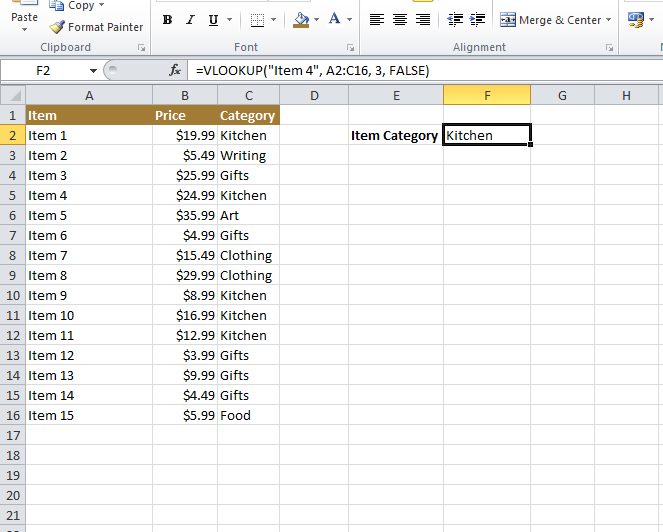
Finding Category in Two Columns
=VLOOKUP("Item 4", A2:C16, 3, FALSE)
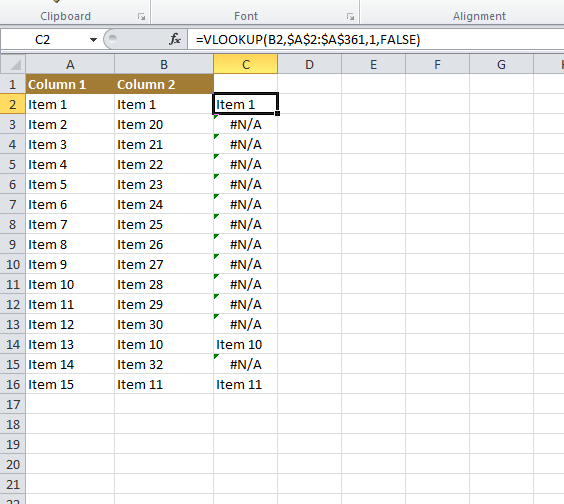
Finding Matching Data in Two Columns
=VLOOKUP(B2,$A$2:$A$361,1,FALSE)
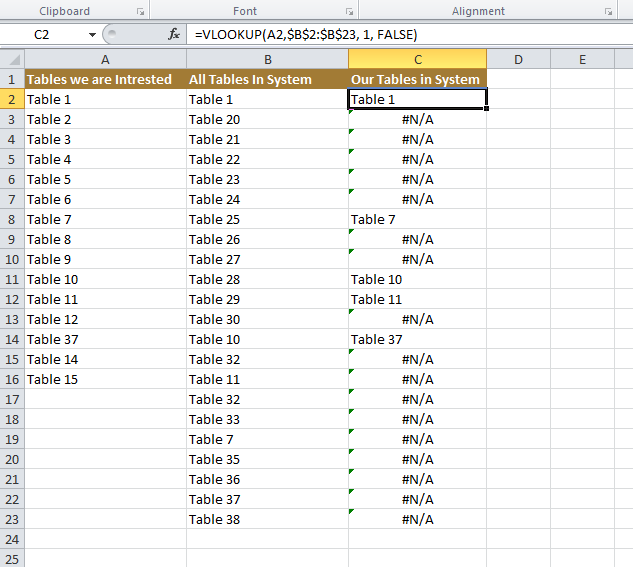
Filter Tables in System
The Super set column in which the sub set is searched should be added as a second parameter. In our case its B
=VLOOKUP(A2,$B$2:$B$23, 1, FALSE)