What is Design Thinking?
Author Archives: admin
Can we instantiate abstract class
Is it possible to create Object for abstract class?
abstract class my {
public void mymethod() {
System.out.print("Abstract");
}
}
class poly {
public static void main(String a[]) {
my m = new my() {};
m.mymethod();
System.out.println(m.getClass().getSuperclass());
}
}
No, we can’t.The abstract super class is not instantiated by us but by java.
In the above code we are creating object for anonymous class.
my m = new my() {};
When the above code is compiled will result in following class file creation
My.class Poly$1.class // Class file corresponding to anonymous subclass Poly.class
anonymous inner type allows you to create a no-name subclass of the abstract class
When the above code is run the output would be
Output
Abstract class my
Now lets override the method in anonymous inner class like one below.
abstract class my {
public void mymethod() {
System.out.print("Abstract");
}
}
class poly {
public static void main(String a[]) {
my m = new my() {
public void mymethod() {
System.out.print("Overridden in anonymous class");
}
};
m.mymethod();
System.out.println(m.getClass().getSuperclass());
}
}
Output
Overridden in anonymous class class my
Anonymous inner class with same name as abstract class are child classes of abstract class.
Interface vs Inheritance
There may be times where one may think that I can extend parent class instead of implementing interface. Lets see whats When to choose inheritance over an interface and interface over inheritance.
inheritance over an interface
The main drawback of interfaces is that they are much less flexible than classes when it comes to allowing for the evolution of APIs. Once you ship an interface, the set of its members is fixed forever. Any additions to the interface would break existing types implementing the interface.
A class offers much more flexibility. You can add members to classes that you have already shipped. As long as the method is not abstract (i.e., as long as you provide a default implementation of the method), any existing derived classes continue to function unchanged.
interface over inheritance
Lets take the following code
Mammal.java
public abstract class Animal
{
public void abstract mate();
public void abstract feed();
}
Now the above abstract class has two methods mate() and feed().
public class Dog extends Animal
{
}
public class Cat extends Animal
{
}
Now we have Dog and Cat concrete classes extending Animal.
we have few more classes extending Animal
public class Giraffe extends Animal{}
public class Rhinoceros extends Animal{}
public class Hippopotamus extends Animal{}
Now the classes Dog and Cat are pet animals. So it should implement pet behavior. This can be done in two ways.
- By defining isPet() method in base class and overriding in child class
- By implementing pettable interface.
Now implementing interface is easy compared to overriding method defined in base class because
- Interface favours clean code. Defining and Overriding the class may increase code redundancy
-
Now you get a parakeets which is again a pet and could also fly.If you are inheriting the base class then you need to add canFly() method in base class and set it to return false and override in the parakeets class to return true.
public class parakeets extends Animal { . . public boolean canFly() { return true; } }Instead you can declare a interface flyable and implement the interface method without making changes to base class
public class parakeets extends Animal implements flyable { . . public boolean canFly() { return true; } } - Interface may be completely not related to class in which it is implemented. Say lets define a carpenter ants class which always moves one after another.Now this can be represented to implement queuing interface which has nothing to do with other animals other then carpenter ants since only ants of this type follows a queue system when they migrate from one place to another
interface or Implementation Which comes First
Scenario 1:
If you have a clear analysis and Design in UML then you can start with the interface.
Scenario 2:
The interface shows up when you need to refactor common features out of several classes.Until you have multiple classes with common features, it’s hard to foresee what the interface should be.
Write a class and extract interface later. Usually the reason for extracting an interface is the need for a second implementation of that interface (often as a mock for unit testing)
ET Notes
[content_protector password=”@pple” identifier=”mugil” cookie_expires=”3600″ ajax=”true”]
http://www.javased.com/index.php?api=org.apache.poi.hssf.usermodel.HSSFFont
“Economic Times Notes”
[gdoc key=”https://docs.google.com/spreadsheets/d/16dFWCuGmc8ZniJ-DRAfh2P4cnf9lbeE2z-l30NPXnCQ/edit?usp=sharing”]
[/content_protector]
Maven vs ant
Maven acts as both a dependency management tool – it can be used to retrieve jars from a central repository or from a repository you set up – and as a declarative build tool. The difference between a “declarative” build tool and a more traditional one like ant or make is you configure what needs to get done, not how it gets done. For example, you can say in a maven script that a project should be packaged as a WAR file, and maven knows how to handle that.
Maven relies on conventions about how project directories are laid out in order to achieve its “declarativeness.” For example, it has a convention for where to put your main code, where to put your web.xml, your unit tests, and so on, but also gives the ability to change them if you need to.
Funds basis
Mutual funds vs hedge funds
Similarities:
Both mutual funds and hedge funds are managed portfolios. This means that a manager (or a group of managers) picks securities that he or she feels will perform well and groups them into a single portfolio. Portions of the fund are then sold to investors who can participate in the gains/losses of the holdings. The main advantage to investors is that they get instant diversification and professional management of their money.
Differences:
Hedge funds are managed much more aggressively than their mutual fund counterparts. They are able to take speculative positions in derivative securities such as options and have the ability to short sellstocks. This will typically increase the leverage- and thus the risk – of the fund. This also means that it’s possible for hedge funds to make money when the market is falling. Mutual funds, on the other hand, are not permitted to take these highly leveraged positions and are typically safer as a result.
Another key difference between these two types of funds is their availability. Hedge funds are only available to a specific group of sophisticated investors with high net worth
Interest Calculation Basics
A flat interest rate means that the amount of interest paid is fixed and does not reduce as time moves on. In other words, the amount of payable interest does not decrease as the loan gets paid off each month.
if you take a loan of Rs 1, 00,000 with a flat rate of interest of 10% p.a. for 5 years, then you would pay:
Rs 20,000 (principal repayment @ 1, 00,000 / 5) + Rs 10,000 (interest @10% of 1, 00,000) = Rs 30,000 every year or Rs 2,500 per month.
Over the entire period, you would actually be paying Rs. 1, 50,000 (2,500 * 12* 5). Therefore, in this example, the monthly EMI of Rs. 2,500 converts to an Effective Interest Rate of 17.27% p.a.
Advantage
During a regime of credit restriction interest rates rise high, if repo rate is increased. So many borrower prefer flat interest rate to reduce interest liability over the sanction term.
Disadvantage
If there is no credit restriction, interest rates come down due to easy availability of credit. At that time flexible interest rate is preferable as interest burden goes down.
The reducing interest rate on the other hand means that as a payment is made on the principal amount of a loan, the interest payment reduces as well.
if you take a loan of Rs 1, 00,000 with a reducing rate of interest of 10% p.a. for 5 years, then your EMI amount would reduce with every repayment. In the first year, you would pay Rs 10, 000 as interest; in the second year you would pay Rs. 8,000 on a reduced principal of Rs. 80,000 and so on, till the last year, you would pay only Rs. 2,000 as interest. Unlike the fixed rate method, you would end up paying Rs. 1.3 lakh instead of Rs. 1.5 lakh.
Flat interest rates generally range from 1.7 to 1.9 times more when converted into the Effective Interest Rate equivalent.
To convert the Flat to Reducing Interest rate multiply by 1.8.
Why RBI banned Zero EMI
In general, as interest rates are lowered, more people are able to borrow more money. The result is that consumers have more money to spend, causing the economy to grow and inflation to increase. The opposite holds true for rising interest rates.
How could any bank offer any loan at Zero percent when they borrow at a cost from a depositor, pay salaries, rent, admin etc. So they must be charging the customer in some manner to get a return but show zero percent ROI to customer. RBI thought this is not a transparent and fair practice and so stopped it.
certain banks where charging hidden fees from the customers or getting discounts from the manufacturer and not passing it through to the Consumer
Why RBI hikes interest Rates to curb Inflation
Inflation, by definition, is an increase in the price of goods and services within an economy. It’s caused due to an imbalance in the goods and buyer ratio – when the demand of goods or services in an economy is higher than the supply, prices go up. Inflation isn’t necessarily a bad thing. It’s often an indicator of a robust economy and the government usually takes into account a yearly rate of 2% to 3% when it comes to an increase in inflation.
The interest rate is the rate at which interest is paid by borrowers for the use of money that they borrow from creditors.
Lower interest rates translate to more money available for borrowing, making consumers spend more. The more consumers spend, the more the economy grows, resulting in a surge in demand for commodities, while there’s no change in supply. An increase in demand which can’t be met by supply results in inflation.
Higher interest rates make people cautious and encourage them to save more and borrow less. As a result, the amount of money circulating in the market reduces. Less money, of course, would mean that consumers find it more difficult to buy goods and services. The demand is less than the supply, the hike in prices stabilise, and sometimes, prices even come down.
A growing economy might sound like music to your ears, but if you think about it, an economy growing at an alarming rate might not really be the best thing.
In a stable and healthy economy, wage and inflation rise in hand in hand.
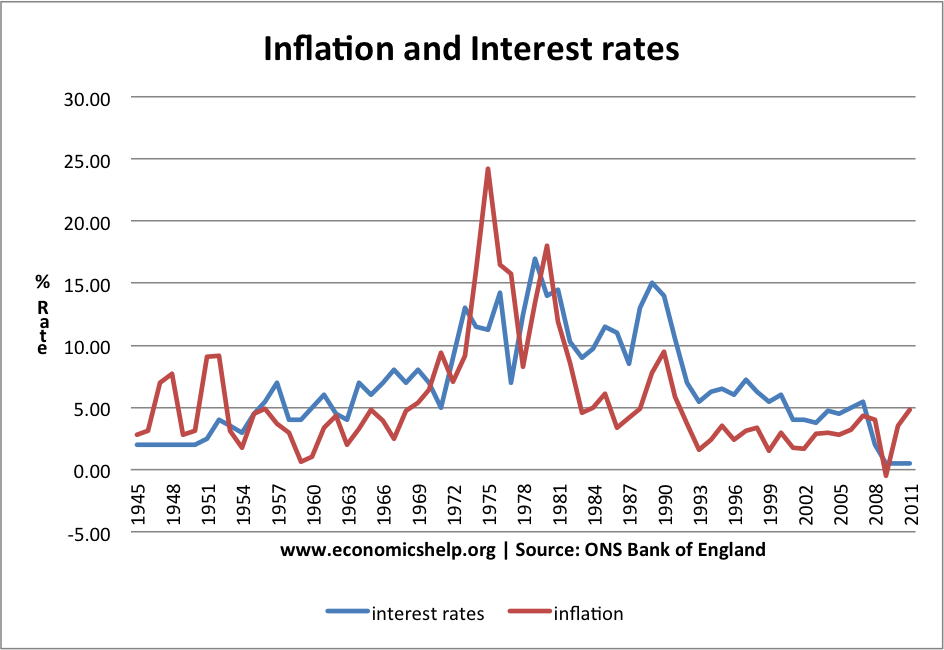
A cut in the interest rates right now will devalue the Rupee further. Imports will be more expensive. Inflation will go up.
The ‘Rule of 72‘ is a simplified way to determine how long an investment will take to double, given a fixed annual rate of interest. By dividing 72 by the annual rate of return, investors can get a rough estimate of how many years it will take for the initial investment to duplicate itself
Years to double investment = 72/compound annual interest rate
Protected: How to sort arraylist using object property
Comparable vs Comparator
Comparable is for objects with a natural ordering. The object itself knows how it is to be ordered.If any class implement Comparable interface in Java then collection of that object either List or Array can be sorted automatically by using Collections.sort() or Arrays.sort() method and object will be sorted based on there natural order defined by CompareTo method.
Comparator is for objects without a natural ordering or when you wish to use a different ordering.
Natural ordering is the Ordering implemented on the objects of each class. This ordering is referred to as the class’s natural ordering.For example Strings Natural Ordering is defined in String Class
Comparable
Compares object of itself with some other objects.Comparable overrides compareTo
Employee.java
package com.acme.users;
public class Employee implements Comparable<Employee> {
public String EmpName;
public Integer EmpId;
public Integer Age;
public Employee(Integer pEmpId, String pEmpName, Integer pAge)
{
this.EmpName = pEmpName;
this.EmpId = pEmpId;
this.Age = pAge;
}
public String getEmpName() {
return EmpName;
}
public void setEmpName(String empName) {
EmpName = empName;
}
public Integer getEmpId() {
return EmpId;
}
public void setEmpId(Integer empId) {
EmpId = empId;
}
public Integer getAge() {
return Age;
}
public void setAge(Integer age) {
Age = age;
}
@Override
public int compareTo(Employee arg0)
{
if(this.getEmpId() == arg0.getEmpId())
return 0;
else if (this.getEmpId() > arg0.getEmpId())
return 1;
else
return -1;
}
}
EmpDashBoard.java
package com.acme.users;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
public class EmpDashBoard {
public static void main(String[] args) {
List<Employee> arrEmpList = new ArrayList();
Employee objEmp1 = new Employee(101, "Ahmed", 31);
Employee objEmp2 = new Employee(127, "Mahesh", 24);
Employee objEmp3 = new Employee(109, "Viparna", 85);
Employee objEmp4 = new Employee(101, "Abdul", 26);
Employee objEmp5 = new Employee(104, "Muthu", 23);
Employee objEmp6 = new Employee(115, "Monalisa", 25);
arrEmpList.add(objEmp1);
arrEmpList.add(objEmp2);
arrEmpList.add(objEmp3);
arrEmpList.add(objEmp4);
arrEmpList.add(objEmp5);
arrEmpList.add(objEmp6);
System.out.println("Sorted based on Natural Sorting(Emp Id)");
System.out.println("Before Sorting");
dispListContent(arrEmpList);
Collections.sort(arrEmpList);
System.out.println("After Sorting");
dispListContent(arrEmpList);
}
public static void dispListContent(List<Employee> parrEmployeeLst) {
System.out.println(" ");
System.out.println("EmpId" + " " + "EmpName" + " " + "Age");
System.out.println("---------------------------");
for (Employee object : parrEmployeeLst) {
System.out.print(object.getEmpId() + " ");
System.out.print(object.getEmpName() + " ");
System.out.println(object.getAge() + " ");
}
}
}
Output
Sorted based on Natural Sorting(Emp Id) Before Sorting EmpId EmpName Age --------------------------- 101 Ahmed 31 127 Mahesh 24 109 Viparna 85 101 Abdul 26 104 Muthu 23 115 Monalisa 25 After Sorting EmpId EmpName Age --------------------------- 101 Ahmed 31 101 Abdul 26 104 Muthu 23 109 Viparna 85 115 Monalisa 25 127 Mahesh 24
Comparator
In some situations, you may not want to change a class and make it comparable. In such cases, Comparator can be used.Comparator overrides compare
Comparator provides a way for you to provide custom comparison logic for types that you have no control over.
In the below Example I have Sorted the Employee class Objects based on Name(EmpNameComparator), Age(EmpAgeComparator) and based on EmpIDName(EmpIdNameComparator)
EmpDashBoard.java
package com.acme.users;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
public class EmpDashBoard {
public static void main(String[] args) {
List<Employee> arrEmpList = new ArrayList();
Employee objEmp1 = new Employee(101, "Ahmed", 31);
Employee objEmp2 = new Employee(127, "Mahesh", 24);
Employee objEmp3 = new Employee(109, "Viparna", 85);
Employee objEmp4 = new Employee(101, "Abdul", 26);
Employee objEmp5 = new Employee(104, "Muthu", 23);
Employee objEmp6 = new Employee(115, "Monalisa", 25);
arrEmpList.add(objEmp1);
arrEmpList.add(objEmp2);
arrEmpList.add(objEmp3);
arrEmpList.add(objEmp4);
arrEmpList.add(objEmp5);
arrEmpList.add(objEmp6);
System.out.println("Sorted based on Natural Sorting(Emp Id)");
System.out.println("Before Sorting");
dispListContent(arrEmpList);
System.out.println("Sorting based on Emp Name");
Collections.sort(arrEmpList, new EmpNameComparator());
dispListContent(arrEmpList);
System.out.println("Sorting based on Emp Age");
Collections.sort(arrEmpList, new EmpAgeComparator());
dispListContent(arrEmpList);
System.out.println("Sorting based on EmpId and Name");
Collections.sort(arrEmpList, new EmpIdNameComparator());
dispListContent(arrEmpList);
}
public static void dispListContent(List<Employee> parrEmployeeLst) {
System.out.println(" ");
System.out.println("EmpId" + " " + "EmpName" + " " + "Age");
System.out.println("---------------------------");
for (Employee object : parrEmployeeLst) {
System.out.print(object.getEmpId() + " ");
System.out.print(object.getEmpName() + " ");
System.out.println(object.getAge() + " ");
}
}
}
EmpNameComparator.java
public class EmpNameComparator implements Comparator<Employee>{
@Override
public int compare(Employee o1, Employee o2) {
String a = o1.getEmpName();
String b = o2.getEmpName();
//Strings Natural Order Comparable Method
int compare = a.compareTo(b);
if (compare > 0){
return 1;
}
else if (compare < 0) {
return -1;
}
else {
return 0;
}
}
}
EmpAgeComparator.java
public class EmpAgeComparator implements Comparator<Employee> {
@Override
public int compare(Employee o1, Employee o2) {
Integer a = o1.getAge();
Integer b = o2.getAge();
if (a > b){
return 1;
}
else if (a < b) {
return -1;
}
else {
return 0;
}
}
}
EmpIdNameComparator.java
public class EmpIdNameComparator implements Comparator<Employee>{
@Override
public int compare(Employee o1, Employee o2) {
String a = o1.getEmpName();
String b = o2.getEmpName();
int i = Integer.compare(o1.getEmpId(), o2.getEmpId());
if (i != 0) return i;
return a.compareTo(b);
}
}
Output
Before Sorting EmpId EmpName Age --------------------------- 101 Ahmed 31 127 Mahesh 24 109 Viparna 85 101 Abdul 26 104 Muthu 23 115 Monalisa 25 Sorting based on Emp Name EmpId EmpName Age --------------------------- 101 Abdul 26 101 Ahmed 31 127 Mahesh 24 115 Monalisa 25 104 Muthu 23 109 Viparna 85 Sorting based on Emp Age EmpId EmpName Age --------------------------- 104 Muthu 23 127 Mahesh 24 115 Monalisa 25 101 Abdul 26 101 Ahmed 31 109 Viparna 85 Sorting based on EmpId and Name EmpId EmpName Age --------------------------- 101 Abdul 26 101 Ahmed 31 104 Muthu 23 109 Viparna 85 115 Monalisa 25 127 Mahesh 24
comparable for natural order, (natural order definition is obviously open to interpretation), and write a comparator for other sorting or comparison needs.
If there is a natural or default way of sorting Object already exist during development of Class than use Comparable. This is intuitive and you given the class name people should be able to guess it correctly like Strings are sorted chronically, Employee can be sorted by there Id etc. On the other hand if an Object can be sorted on multiple ways and client is specifying on which parameter sorting should take place than use Comparator interface. for example Employee can again be sorted on name, salary or department and clients needs an API to do that. Comparator implementation can sort out this problem.