How to highlight rows which have different row value of one Column
The Steps are as Below
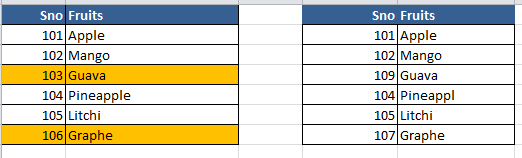
Below is the way to highlight the rows based on a change in value in the single column.The Column considered is SNo
Steps
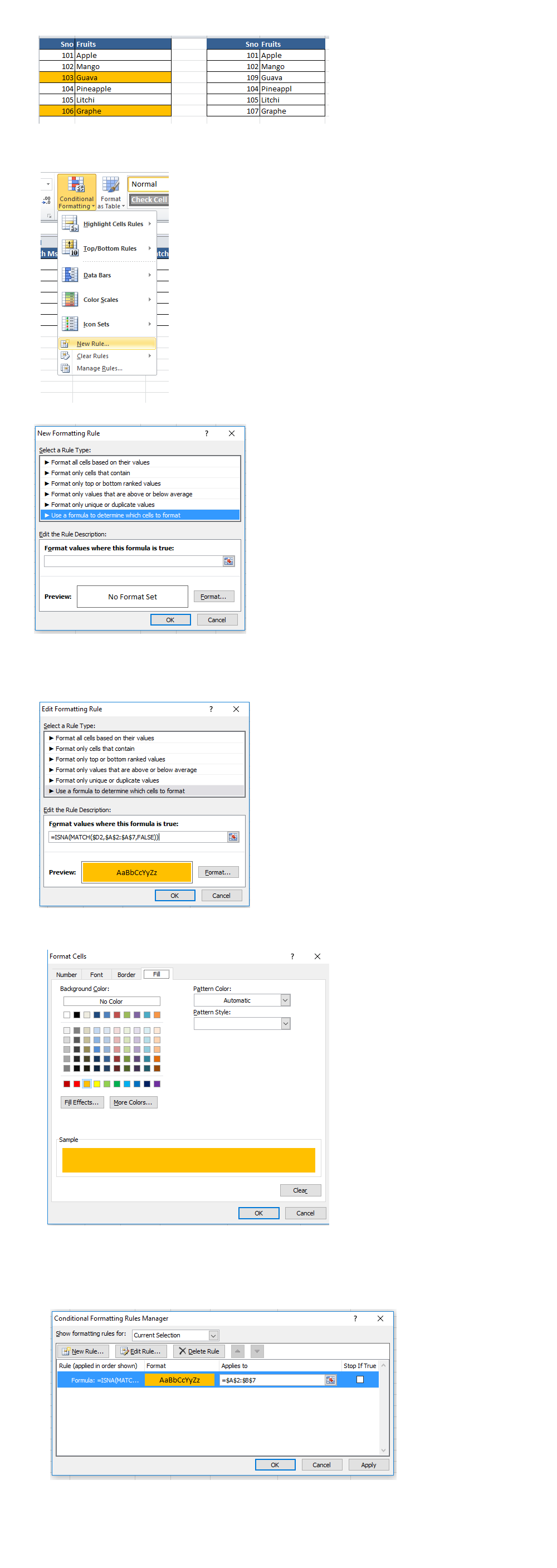
- Select the whole DataSet LookUpArray on which the conditional formatting to be applied
- Click on Conditional Formatting
- Click on new Rule
- Use a formula to determine which cells to format
- Note : The formula used is relative formula =ISNA(MATCH($D2,$A$2:$A$7,FALSE))
- Use the format option to apply the Conditional format on the cells
- The same could be seen in Conditional Formatting->Manage Rules for future rule edits
In the below image Rows 4 and 7 are highlighted because of mismatch in SNo and 5 is highlighted because of mismatch in fruit name
Checking for Identical rows in two tables with more than one column
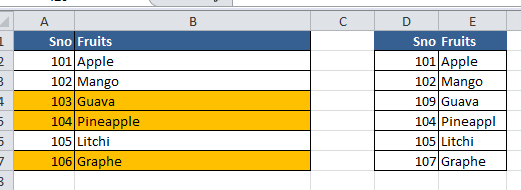
=ISNA(MATCH($D2,$A$2:$A$7,FALSE)&MATCH($E2,$B$2:$B$7,FALSE) )
Steps
- First we are checking if the rows in D2 is same as on in A2 to A7
- Second we are checking if the rows in E2 is same as on in B2 to B7
