Why CLOUD?
SCALABILITY – The advantage of cloud is you can setup servers on demand and pay only for usage. SCALABILITY
INSTANT – Quick fix like plugins instead of long time for configuring hosting servers
MONEY – Pay for what you use.
What is SaaS, PaaS and IaaS? With examples
IAAS (Infrastructure As A Service) :
The base layer
Deals with Virtual Machines, Storage (Hard Disks), Servers, Network, Load Balancers etc
IaaS (Infrastructure as a Service), as the name suggests, provides you the computing infrastructure, physical or (quite often) virtual machines and other resources like virtual-machine disk image library, block and file-based storage, firewalls, load balancers, IP addresses, virtual local area networks etc.
Examples: Amazon EC2, Windows Azure, Rackspace, Google Compute Engine.
PAAS (Platform As A Service) :
A layer on top on PAAS
Runtimes (like java runtimes), Databases (like mySql, Oracle), Web Servers (tomcat etc)
PaaS (Platform as a Service), as the name suggests, provides you computing platforms which typically includes operating system, programming language execution environment, database, web server etc.
Examples: AWS Elastic Beanstalk, Windows Azure, Heroku, Force.com, Google App Engine, Apache Stratos.
SAAS (Software As A Service) :
A layer on top on PAAS
Applications like email (Gmail, Yahoo mail etc), Social Networking sites (Facebook etc)
While in SaaS (Software as a Service) model you are provided with access to application software often referred to as “on-demand software”. You don’t have to worry about the installation, setup and running of the application. Service provider will do that for you. You just have to pay and use it through some client.
Examples: Google Apps, Microsoft Office 365.
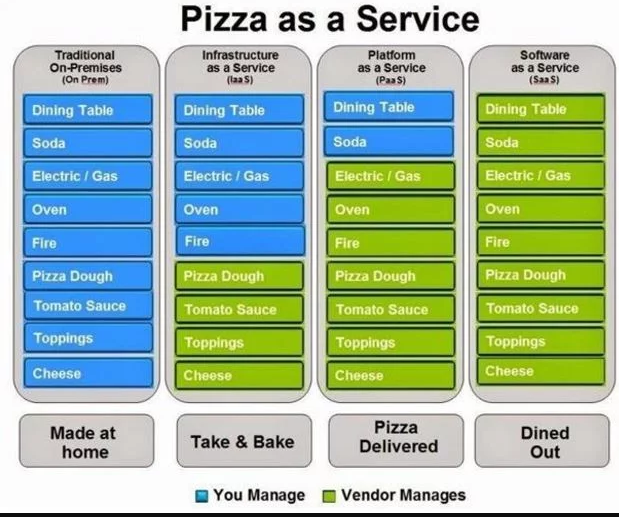
Pizza as a Service
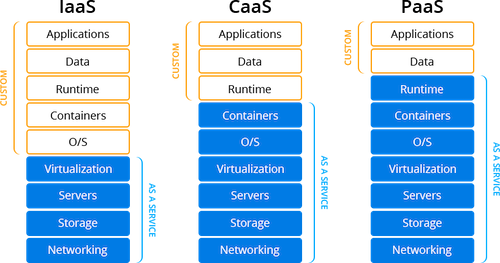
IAAS vs SAAS vs PAAS
Traditional vs CloudNative Applications
TRADITIONAL APPLICATION uses sticky servers which sticks to one User – one Server. If the server goes down then transition from one to another removes the user session in the first server.
CLOUD NATIVE APPLICATION are non sticky servers.The server maintains a shared state by many ways like using
backend database or usings session stores.
What is SERVERLESS?
SERVERLESS doesnot mean no server, rather you would be using someones server.Cloud is serverless.
‘Serverless’, like many things in our space, is becoming an overloaded term.. but generally what it means is “Functionally, Our architecture does not depend on the provisioning or ongoing maintenance of a server”
The first instance that comes to mind is a single page javascript app, that uses local storage, and is stored on something like Amazon S# or Github Pages (or any static site – those are just common examples). Imagine something like a ‘todo’ or ‘getting things done’-style application that runs entirely in your browser. Your browser hits a service like S3 to download the code, and the items you store are all stored in local storage in your browser. There is no server you maintain for this.
The second instance, and is a bit more complicated (and also the one that popularized the term ‘serverless’), uses a service like AWS Lambda. Let me explain this by presenting the problem it solves:
Many times in my career I’ve solved a business problem for a client with little more than some ruby code that performed a periodic extract, transform, and load (typically written as a rake task). Once solved, I’d typically automate it with cron. Then the problem becomes ‘where do I host this thing that runs once every hour?’ For some clients, we’d set up a server in their existing infrastructure. For others, we’d set up an EC2 instance, even though it was idle 99% of the time. In either of those circumstances, there is a server that requires provisioning, patching, monitoring, updating, etc.
With Amazon Lambda, I can take that rake task and run it on their service as a pure ‘function’. I can even schedule it. No longer would that client need a piece of infrastructure for such a simple once-an-hour thing.
With ‘serverless’ there is still a server, just like with ‘cloud’ there is still a computer. There is just a level of abstraction on top of it that takes some of the environmental responsibilities for you.
Azure vs AWS?
Azure: Azure users choose Virtual Hard Disk (VHD), which is equivalent to a Machine Instance, to create a VM. VHD can be pre-configured by Microsoft, the user or a third party. The user must specify the amount of cores and memory.
Storage AWS: AWS has temporary storage that is allocated once an instance is started and destroyed when the instance is terminated. They also provide block storage (same as hard disks), that can be separate or attached to an instance. Object storage is offered with S3; and data archiving services with Glacier. Fully supports relational and NoSQL databases and Big Data.
Support Plans AWS: Pricing is based on a sliding scale tied to monthly usage, so your bill could potentially be quite high if you’re a heavy user.
Azure: Users are billed a flat monthly rate.