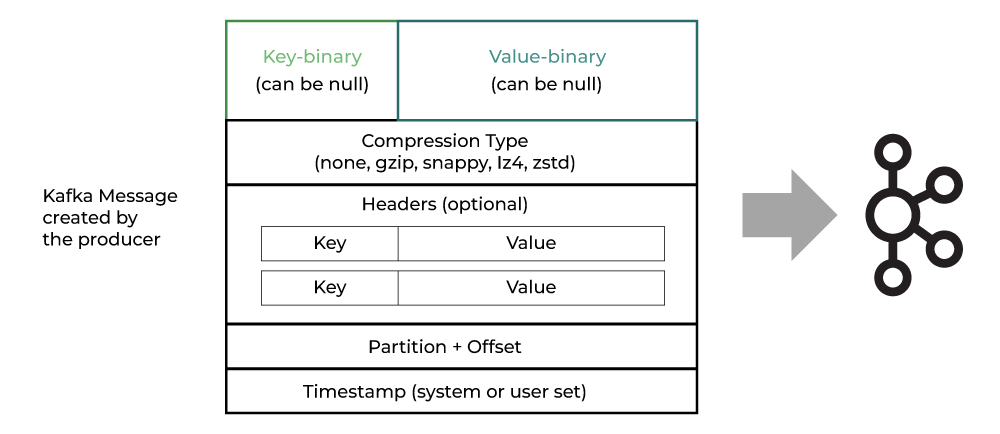
In Kafka, messages are always stored using key value format, with key being the one used for determining the partition after hashing and value the actual data.
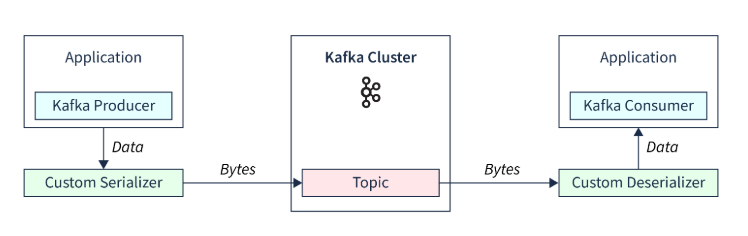
During Writing(message creation), producers uses serializers to convert the messages to bytes format. Kafka employs different kind of serializer based on the datatype which needs to be converted to byte format
Consumers uses deserizliser at their end to convert bytes to original data. Pro
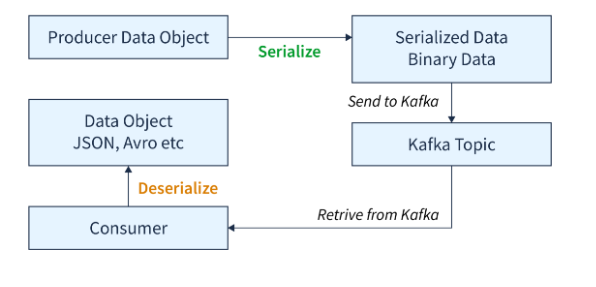
It also allows custom serializer which helps in converting data to byte stream.
How Consumer reads data
Consumer keeps track of data read by having Consumer Offsets. A consumer offset in Kafka is a unique integer that tracks the position of the last message a consumer has processed in a partition
in order to “checkpoint” how far a consumer has been reading into a topic partition, the consumer will regularly commit the latest processed message, also known as consumer offset.
Offsets are important for a number of reasons, including: Data continuity: Offsets allow consumers to resume processing from where they left off if the stream application fails or shuts down.
Sequential processing: Offsets enable Kafka to process data in a sequential and ordered manner. Replayability: Offsets allow for replayable data processing.
When a consumer group is first initialized, consumers usually start reading from the earliest or latest offset in each partition. Consumers commit the offsets of messages they have processed successfully.
The position of the last available message in a partition is called the log-end offset. Consumers can store processed offsets in local variables or in-memory data structures, and then commit them in bulk.
Consumers can use a commit API to gain full control over offsets.
What is Consumer Re balance?
a process by which partitions get reassigned among consumers in a group to ensure that each consumer gets an equal number of partitions to process data.
Moving partition ownership from one consumer to another is called rebalance
A Rebalance happens when:
- a consumer JOINS the group
- a consumer SHUTS DOWN cleanly
- a consumer is considered DEAD by the group coordinator. This may happen after a crash or when the consumer is busy with a long-running processing, which means that no heartbeats has been sent in the meanwhile by the consumer to the group coordinator within the configured session interval
- new partitions are added
Being a group coordinator (one of the brokers in the cluster) and a group leader (the first consumer that joins a group) designated for a consumer group, Rebalance can be more or less described as follows:
- the leader receives a list of all consumers in the group from the group coordinator (this will include all consumers that sent a heartbeat recently and which are therefore considered alive) and is responsible for assigning a subset of partitions to each consumer.
- After deciding on the partition assignment (Kafka has a couple built-in partition assignment policies), the group leader sends the list of assignments to the group coordinator, which sends this information to all the consumers.
Consumer rebalance initiated when consumer requests to join a group or leave a group. The Group Leader receives a list of all active consumers from the Group Coordinator. Group Leader decides partition(s) assigned to each consumer by using Partition Assigner. Once Group Leader finalize partition assignment it sends assignments list to Group Coordinator which send back this information to all consumer. Group only sends applicable partitions to their consumer not other consumer assigned partitions. Only the Group Leader aware of all consumers and their assigned partitions. After the rebalance is complete, consumers start sending Heartbeat to the Group Coordinator that it’s alive. Consumers send an OffsetFetch request to the Group Coordinator to get the last committed offsets for their assigned partitions. Consumers start consuming messaged for newly assigned partition. One of the main concept in rebalance is statemanagement.
State Management
While rebalancing, the Group coordinator set its state to Rebalance and wait for all consumers to re-join the group. When the Group starts rebalancing, the group coordinator first switches its state to rebalance so that all interacting consumers are notified to rejoin the group. Once rebalance completed Group coordinator create new generation ID and notified to all consumers and group proceed to sync stage where consumers send sync request and go to wait until group Leader finish generating new assign partition. Once consumers received a new assigned partition they moved to a stable stage.