How Topics, Partitions and Broker are related
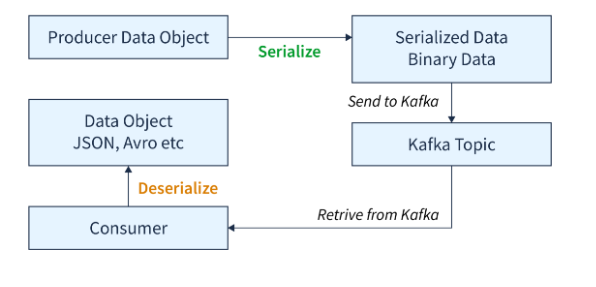
Topics are logical categories or streams of data within Kafka. They act as message queues where producers publish data and consumers retrieve it
Brokers are servers that store and manage topics, and handle communication between producers and consumer
Partitions are the basic unit of data storage and distribution within Kafka topics. They are the main method of concurrency for topics, and are used to improve performance and scalability.
What is Broker Discovery?
A client that wants to send or receive messages from the Kafka cluster may connect to any broker in the cluster. Every broker in the cluster has metadata about all the other brokers and will help the client connect to them as well, and therefore any broker in the cluster is also called a bootstrap server.
- A client connects to a broker in the cluster
- The client sends a metadata request to the broker
- The broker responds with the cluster metadata, including a list of all brokers in the cluster
- The client can now connect to any broker in the cluster to produce or consume data
What is Replication Factor?
the number of copies of a topic’s partitions across different brokers. When Kafka Connects creates a topic, the replication factor should be at least 3 for a production system. A replication factor of 3 is commonly used because it balances broker loss and replication overhead
topic replication does not increase the consumer parallelism
How to choose the replication factor
It should be at least 2 and a maximum of 4. The recommended number is 3 as it provides the right balance between performance and fault tolerance, and usually cloud providers provide 3 data centers / availability zones to deploy to as part of a region.The advantage of having a higher replication factor is that it provides a better resilience of your system. If the replication factor is N, up to N-1 broker may fail without impacting availability if acks=0 or acks=1
The disadvantages of having a higher replication factor is Higher latency experienced by the producers, as the data needs to be replicated to all the replica brokers before an ack is returned if acks=all.More disk space required on your system
If there is a performance issue due to a higher replication factor, you should get a better broker instead of lowering the replication factor
Maximum Replication Factor = No of Brokers in Cluster
What is min.insync.replica?
min.insync.replicas is the minimum number of copies of the data that you are willing to have online at any time to continue running and accepting new incoming messages. min.insync.replica here is 1 by default
What is role of Zookeeper in kafka?
- Electing a controller. The controller is one of the brokers and is responsible for maintaining the leader/follower relationship for all the partitions. When a node shuts down, it is the controller that tells other replicas to become partition leaders to replace the partition leaders on the node that is going away. Zookeeper is used to elect a controller, make sure there is only one and elect a new one it if it crashes.
- Cluster membership – which brokers are alive and part of the cluster? this is also managed through ZooKeeper.
- Topic configuration – which topics exist, how many partitions each has, where are the replicas, who is the preferred leader, what configuration overrides are set for each topic
- (0.9.0) – Quotas – how much data is each client allowed to read and write
- (0.9.0) – ACLs – who is allowed to read and write to which topic (old high level consumer) – Which consumer groups exist, who are their members and what is the latest offset each group got from each partition.
What is bootstrap.servers?
bootstrap.servers provides the initial hosts that act as the starting point for a Kafka client to discover the full set of alive servers in the cluster. bootstrap.servers is a configuration we place within clients, which is a comma-separated list of host and port pairs that are the addresses of the Kafka brokers in a “bootstrap” Kafka cluster that a Kafka client connects to initially to bootstrap itself.
Since these servers are just used for the initial connection to discover the full cluster membership (which may change dynamically), this list does not have to contain the full set of servers (you may want more than one, though, in case a server is down).
It is the URL of one of the Kafka brokers which you give to fetch the initial metadata about your Kafka cluster. The metadata consists of the topics, their partitions, the leader brokers for those partitions etc. Depending upon this metadata your producer or consumer produces or consumes the data.
You can have multiple bootstrap-servers in your producer or consumer configuration. So that if one of the broker is not accessible, then it falls back to other.
Kafka default partitioner doesnt pitch in until the data reaches 16KB
What is Consumer Group?
If more than one consumer comes togeather and tries to read topic, in such case topic which is split across various partitions would be read by various consumer in group.
Is it always one consumer is assigned to one partition of Topic?
The consumers in a group divide the topic partitions as fairly amongst themselves as possible by establishing that each partition is only consumed by a single consumer from the group. When the number of consumers is lower than partitions, same consumers are going to read messages from more than one partition.
If a single consumer is going to read from all your partitions. This type of consumer is known as exclusive consumer.
The number of partitions should be equal to the number of consumers
the number of consumers be greater, the excess consumers were to be idle, wasting client resources. If the number of partitions is greater, some consumers will read from multiple partitions, which should not be an issue unless the ordering of messages is important.
Does kafka ensures ordering of messages across multiple Partitions?
Kafka does not guarantee ordering of messages between partitions. It does provide ordering within a partition. Therefore, Kafka can maintain message ordering for a consumer if it is subscribed to only a single partition. If message ordering is required then messages send from producer should be using a same partition key to be grouped into same partition in kafka broker.
Could there be a scenario where a partition would be read multiple times?
Yes. If the Partitions are read by more than one consumers from different consumer group. Note: Consumers from same group could not read same partitions more than once.