Kafka
One of the activity in application is to transfer data from Source System to Target System. Over period of time this communication becomes complex and messy. Kafka provides simplicity to build real-time streaming data pipelines and real-time streaming applications.Kafka Cluster sits in the middle of Source System and Target System. Data from Source System is moved to Cluster by Producer and Data from Cluster is moved from to Target System by Consumer.
Source System -> {Producer} -> [Kafka Cluster] -> {Consumer} -> Target System
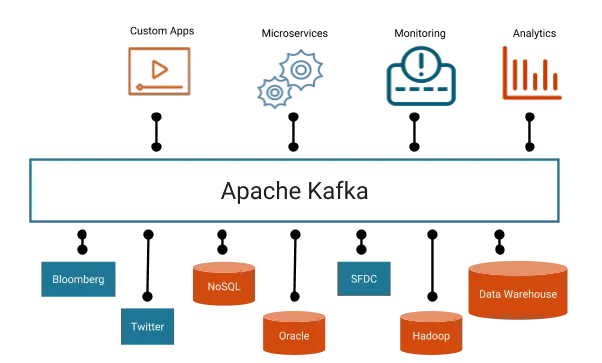
Kafka Provides Seamless integration across applications hosted in multiple platforms by acting as a intermediate.
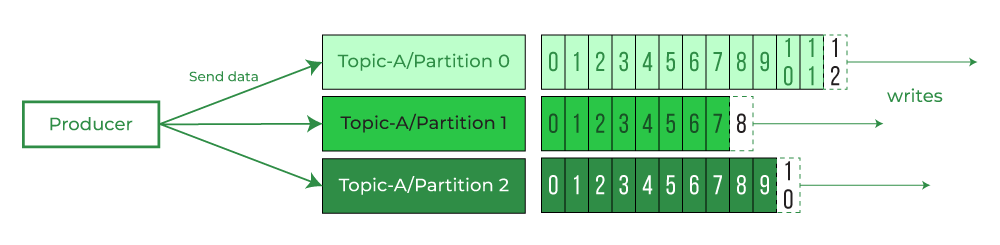
- Sequence of message are called Data Stream. Topic is a particular stream of Data. Topics are organized inside cluster. Topics are like rows in a database which are identified by Topic name.
- Cluster Contains Topics -> Topics contains Data Stream -> Data Stream is Made of Seq of Messages
- To add(write) Data to Topic, we use Kafka Producer and to read data we use kafka consumers.
- Topics
- What is Topic? Topics are the categories used to organize messages.Topics are like rows in a table which are identified by Topic name(table name).
- Why it is Needed? Logical channel for producers to publish messages and consumers to receive them I.E. Processing payments, Tracking Assets, Monitoring patients, Tracking Customer Interactions
- How it works? Logical channel for producers to publish messages and consumers to receive them.A topic is a log of events. Logs are easy to understand, because they are simple data structures with well-known semantics.
- Partitions
- What are Partitions ? Topics are split into multiple partitions. Messages sent to Topic end up in these partitions, and the messages are ordered by Id(Kafka Partition Offsets). A partition in Kafka is the storage unit that allows for a topic log to be separated into multiple logs and distributed over the Kafka cluster.
Partitions are immutable. Once data written to partition cannot be changed. Data is kept for one Week which is default configuration. - Why Partition is needed? Partitions allow Kafka to scale horizontally by distributing data across multiple brokers.Multiple consumers can read from different partitions in parallel, and multiple producers can write to different partitions simultaneously. Each partition can have multiple replicas spread across different brokers.
- How Partition works? By breaking a single topic log into multiple logs, which are then spread across one or more brokers. This allows Kafka to scale and handle large amounts of data efficiently
- What are Partitions ? Topics are split into multiple partitions. Messages sent to Topic end up in these partitions, and the messages are ordered by Id(Kafka Partition Offsets). A partition in Kafka is the storage unit that allows for a topic log to be separated into multiple logs and distributed over the Kafka cluster.
-
Broker
- What is Broker? is a server that manages the flow of transactions between producers and consumers in Apache Kafka. Kafka brokers store data in topics, which are divided into partitions. Each broker hosts a set of partitions. Brokers handle requests from clients to write and read events to and from partitions
- How Broker works?One broker acts as the Kafka controller (Kafka Broker Leader), which does administrative task, maintaining the state of the other brokers, health check of brokers and reassigning work
- Why Broker is required?Producers connect to a broker to write events, while consumers connect to read events.
- Offset
- What is Offset? Offset is a unique identifier for a message in a Kafka partition. An offset is an integer that represents the position of a message in a partition’s log. The first message in a partition has an offset of 0, the second message has an offset of 1, and so on.
- Why it needed? Offsets enable Kafka to provide sequential, ordered, and replayable data processing. This numerical value helps Kafka keep track of progress within a partition. It also allows Kafka to scale horizontally while staying fault-tolerant.
- How it works? When a producer publishes a message to a Kafka topic, it’s appended to the end of the partition’s log and assigned a new offset. Consumers maintain their current offset, which indicates the last processed message in each partition.
- Producer
- What is Producer? Producer writes data to Kafka broker which would be picked by consumer. A producer can send anything, but it’s typically serialized into a byte array. It can also include a message key, timestamp, compression type, and headers.
- How Producer works? A producer writes messages to a Kafka broker, which then adds a partition and offset ID to the message.
- Why Producer is needed? It allows applications to send streams of data to the Kafka cluster
- Producer uses partitioner to decide to which partition the data should write. Producer doesnot decided the broker rather it endup in the respective broker because of the partition presence.
- Producer has message keys in message which they send. If the key is null, the data is sent using a round-robin mechanism for writing. If the key is not null, then it would end up in the same partition based on the key. Message ordering is possible with key
- Consumer
- What is Consumer? Consumer reads data from Kafka broker.
- How Consumer works? A consumer issues fetch requests to brokers for partitions it wants to consume. It specifies a log offset, and receives a chunk of log that starts at that offset position. The consumer should know in advance the format of the message.
- Why Consumer is needed? It allows applications to receive streams of data from the Kafka broker
- Consumer Group
- What is Consumer Group? a collection of consumer applications that work together to process data from topics in parallel
- How Consumer Group works? A consumer group divides the partitions of a topic among its consumers. Each consumer is assigned a subset of partitions, and only one consumer can process a given partition.
- Why Consumer group is needed?allow multiple consumers to work together to process events from a topic in parallel. This is important for scalability, as it enables consumers to read from many events simultaneously.
-
Messages
- What is Message?Kafka messages are created by the producer using serialization mechanism
- How Message works? Kafka messages are stored as serialized bytes and have a key-value structure
- Why Message is needed? Basic Unit of data in Kafka
- Key is a unique identifier of the Partition, which would be null first time. Value is the actual message. Both Key and value would be in Binary format
-
Partioner
- What is Partioner?Kafka’s partitioning feature is a key part of its ability to scale and handle large amounts of data. Partioning is done by partioner
- How Partioner works?A Kafka partitioner uses hashing to determine which partition a message should be sent to. It employs Key hashing technique that allows for related messages to be grouped together and processed in the correct order. For example, if a Kafka producer uses a user ID as the key for messages about various users, all messages related to a specific user will be sent to the same partition.
-
Zookeeper
- What is Zookeeper?ZooKeeper is a software tool that helps maintain naming and configuration data, and provides synchronization within distributed systems
- How Zookeeper works? Zookeeper keeps track of which brokers are part of the Kafka cluster. Zookeeper is used by Kafka brokers to determine which broker is the leader of a given partition and topic and perform leader elections. Zookeeper stores configurations for topics and permissions. Zookeeper sends notifications to Kafka in case of changes (e.g. new topic, broker dies, broker comes up, delete topics, etc.…)