A binary file is a file whose content must be interpreted by a program or a hardware processor that understands in advance exactly how it is formatted. That is, the file is not in any externally identifiable format so that any program that wanted to could look for certain data at a certain place within the file. A progam (or hardware processor) has to know exactly how the data inside the file is laid out to make use of the file.
Hadoop does not work very well with a lot of small files, files that are smaller than a typical HDFS Block size as it causes a memory overhead for the NameNode to hold huge amounts of small files. Also, every map task processes a block of data at a time and when a map task has too little data to process, it becomes inefficient. Starting up several such map tasks is an overhead.
To solve this problem, Sequence files are used as a container to store the small files. Sequence files are flat files containing key, value pairs. A very common use case when designing ingestion systems is to use Sequence files as containers and store any file related metadata(filename, path, creation time etc) as the key and the file contents as the value.
A Sequence file can be have three different formats: An Uncompressed format, a Record Compressed format where the value is compressed and a Block Compressed format where entire records are compressed.There are sync markers for every few 100 bytes (approximately) that represent record boundaries.
Read from Here
- As binary files, these are more compact than text files
- Provides optional support for compression at different levels – record, block.
- Files can be split and processed in parallel
- As HDFS and MapReduce are optimized for large files, Sequence Files can be used as containers for large number of small files thus solving hadoop’s drawback of processing huge number of small files.
- Extensively used in MapReduce jobs as input and output formats. Internally, the temporary outputs of maps are also stored using Sequence File format.
A sequence file consists of a header followed by one or more records. All the three formats uses the same header structure.
- Uncompressed format
- Record Compressed format
- Block-Compressed format
Header Structure of Sequence Files

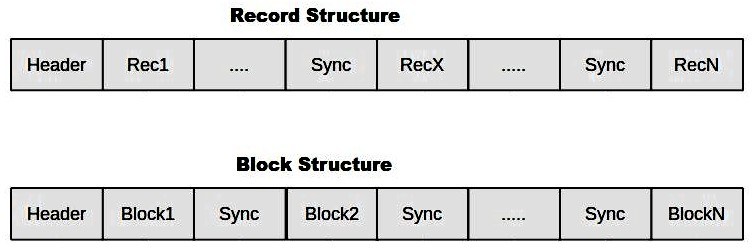
Record Structure of Sequence Files

Block Structure of Sequence Files
Read from Here
e.g. Assume that you are uploading images in facebook and you have to remove duplicate images. You can’t store image in textformat. What you can do : get MD5SUM of image file and if MD5SUM already exists in the system, just discard insertion of duplicate image. In your text file, you can simply have “Date:” and “Number of images uploaded”. Image can be stored out side of HDFS system like CDN network or at some other web server
Read from Here