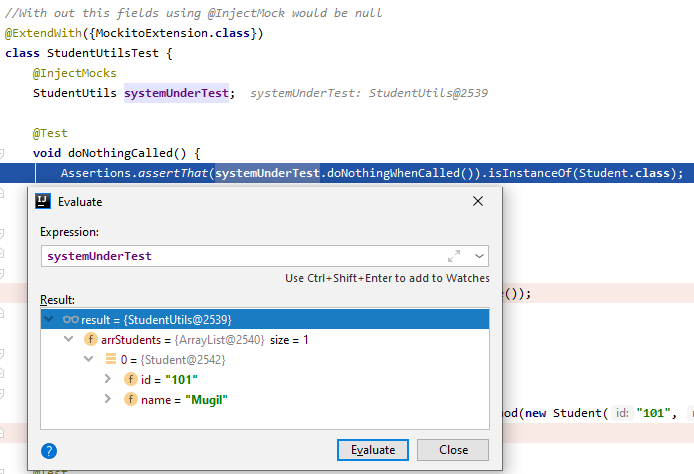
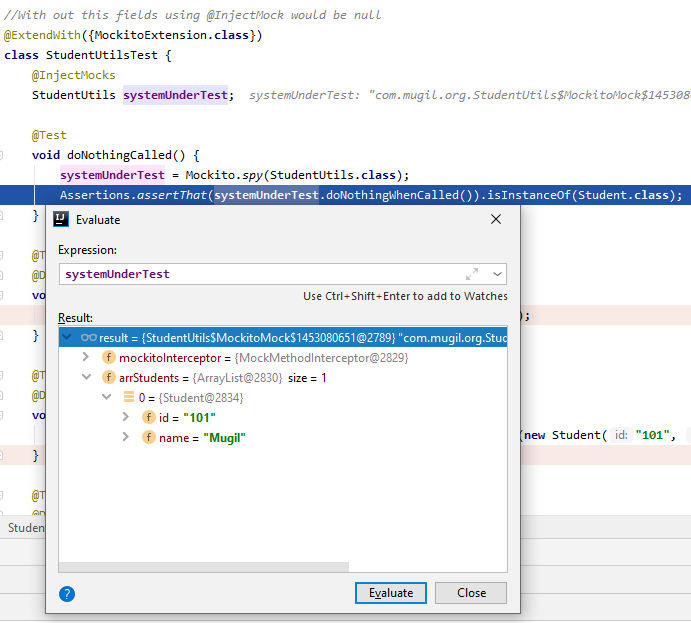
@SpringBootApplication = @Configuration + @ComponentScan + @EnableAutoConfiguration
- @Configuration to enable Java-based configuration
- @ComponentScan – This annotation enables component-scanning so that the web controller classes and other components you create will be automatically discovered and registered as beans in Spring’s Application Context. All the@Controller classes you write are discovered by this annotation..
- @EnableAutoConfiguration annotation tells Spring Boot to “guess” how you will want to configure Spring, based on the jar dependencies that you have added. For example, If HSQLDB is on your classpath, and you have not manually configured any database connection beans, then Spring will auto-configure an in-memory database.For example, if you add spring-boot-starter-web dependency in your classpath, it automatically configures Tomcat and Spring MVC.
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
- Should check whether Java-based configuration are loaded
- Should do component scan and create beans.
- Should assign appropriate beans by resolving
@SpringBootTest annotation is used to bootstrap the entire container. The annotation works by creating the ApplicationContext that will be utilized in our tests. @SpringBootTest annotation works by creating the ApplicationContext used in our tests through SpringApplication.It starts the embedded server, creates a web environment and then enables @Test methods to do integration testing.
- Below we have two class DBConfig.java and DBProperties.java.
- DBConfig loads DBProperties bean. DBProperties bean gets its value from application.yml
- In the below integration test we are going to check whether all the classes are properly getting loaded into application context.
- Classes loaded using @SpringBootTest would be available only in the context of the class in which it is used. Just because you add the list of classes in TestConfigApplicationTests.java it wont be available in other test classes(DatasourceConfigTest.java, ExampleConfigurationTest.java)
DBProperties.java
package com.mugil.org.configs;
import org.springframework.boot.context.properties.ConfigurationProperties;
import java.util.ArrayList;
import java.util.List;
@ConfigurationProperties(prefix = "spring.datasource")
public class DBProperties {
private String userName;
private String password;
public String getUserName() {
return userName;
}
public void setUserName(String userName) {
this.userName = userName;
}
public String getPassword() {
return password;
}
public void setPassword(String password) {
this.password = password;
}
}
DBConfig.java
@Configuration
@EnableConfigurationProperties(DBProperties.class) // Tells from which class is needed for creation of Beans
public class DBConfig {
@Bean
public DBProperties dbProperties(){
DBProperties objDBProperties = new DBProperties();
return objDBProperties;
}
}
application.yml
spring:
profiles:
active: dev
---
spring:
config:
activate:
on-profile: dev
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
password: root
url: jdbc:mysql://localhost:3306/db
username: root
servers:
- www.abc.test.com
- www.xyz.test.com
---
spring:
config:
activate:
on-profile: production
datasource:
driver-class-name: org.h2.Driver
password: sa
url: jdbc:h2:mem:db;DB_CLOSE_DELAY=-1
username: sa
servers:
- www.abc.com
- www.xyz.com
TestConfigApplication.java
package com.mugil.org;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class TestConfigApplication {
public static void main(String[] args) {
SpringApplication.run(TestConfigApplication.class, args);
}
}
@SpringBootTest loads the DBConfig.java and creates DBProperties bean by reading values from application.yml file. The SpringBootTest ensures that all loading of beans defined in configuration file and all the values needed from application.yml and application.properties are available without any issue.
In case if you want to have any class to be autowired in @SpringBootTest class, the same should be defined in @SpringBootTest(classes = DBConfig.class) annotation.
The below @SpringBootTest takes classes which should be available by the time the application is bootstrapped. So we are expecting the properties to be read from application.yml and the bean gets created. Incase there is a problem the test case would fail below.
TestConfigApplication.java
package com.mugil.org;
import com.mugil.org.configs.DBConfig;
import com.mugil.org.configs.DBProperties;
import com.mugil.org.configs.ExampleConfiguration;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
@SpringBootTest(classes = {DBConfig.class})
class TestConfigApplicationTests {
@Autowired
DBProperties dbProperties;
@Test
void contextLoads() {
System.out.println(dbProperties.getUserName());
}
}
Below is a test which check if the value are loaded from yaml and is not null.
DatasourceConfigTest.java
package com.mugil.org.configs;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import static org.junit.jupiter.api.Assertions.assertNotNull;
@SpringBootTest(classes = DBConfig.class)
class DatasourceConfigTest{
//This is same as using context.run method where the beans would be initialized
//context.run method in our case is invoked because of @SpringBootTest defined class
@Autowired
DBProperties dbProperties;
@Test
public void dbConfigTest() throws Exception {
final String name = dbProperties.getUserName();
//We can check whether the property is getting loaded and its not null only not null
assertNotNull(name);
}
}
- The @SpringBootTest annotation tells Spring Boot to look for a main configuration class (one with @SpringBootApplication , for instance) and use that to start a Spring application context.
- Spring Boot Integration Testing is running an application in ApplicationContext and run tests.spring-boot-starter-test which will internally use spring-test and other dependent libraries
- @SpringBootTest annotation works by creating the ApplicationContext used in our tests through SpringApplication.It starts the embedded server, creates a web environment and then enables @Test methods to do integration testing.
ExampleConfiguration.java
package com.mugil.org.configs;
import com.mugil.org.services.ExampleService;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class ExampleConfiguration {
@Bean
ExampleService exampleService() {
ExampleService exampleService = new ExampleService();
return exampleService;
}
}
Below is the testing of the same functionality in a different way. Instead of using @SpringBootTest we are loading the class with help of ApplicationContextRunner and checking whether the loaded class – ExampleConfiguration.java dependencies – ExampleService.java in turn gets loaded
ExampleConfigurationTest.java
package com.mugil.org.configs;
import com.mugil.org.services.ExampleService;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.runner.ApplicationContextRunner;
import static org.assertj.core.api.Assertions.assertThat;
class ExampleConfigurationTest {
/*
* I setup a context runner with the class ExampleConfiguration
* in it. For that, I use ApplicationContextRunner#withUserConfiguration()
* methods to populate the context.
*/
ApplicationContextRunner context = new ApplicationContextRunner()
.withUserConfiguration(ExampleConfiguration.class);
@Test
public void should_check_presence_of_example_service() {
/*
* We start the context, and we will be able to trigger
* assertions in a lambda receiving a
* AssertableApplicationContext
*/
context.run(it -> {
/*
* I can use assertThat to assert on the context
* and check if the @Bean configured is present
* (and unique)
*/
assertThat(it).hasSingleBean(ExampleService.class);
});
}
}
new ApplicationContextRunner() creates a new context and creates the bean by loading the configuration
For further reference check the code in the Link
Below is a static util class which can be used to check the list of beans available in the application context
ExampleConfigurationTest.java
package com.mugil.org.utils;
import org.springframework.beans.BeansException;
import org.springframework.context.ApplicationContext;
import org.springframework.context.ApplicationContextAware;
import org.springframework.stereotype.Service;
@Service
public class SpringUtils implements ApplicationContextAware {
private static ApplicationContext ctx;
@Override
public void setApplicationContext(ApplicationContext appContext)
throws BeansException {
ctx = appContext;
}
public static ApplicationContext getApplicationContext() {
return ctx;
}
}