Q1:What would be the output for the following Program?
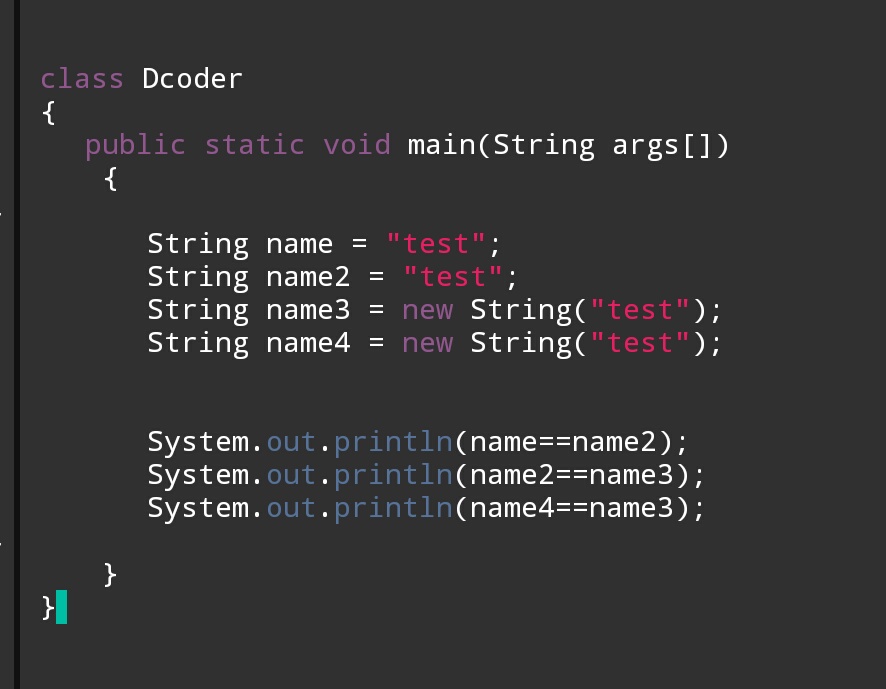
Output:
True
False
False
Question1.java
public class Question1
{
public static void main(String[] args)
{
String Name1 = "Mugil";
String Name2 = "Mugil";
String Name3 = new String("Mugil");
String Name4 = new String("Mugil");
System.out.println(Name1 == Name2);
System.out.println(Name2 == Name3);
System.out.println(Name3 == Name4);
}
}
Output
true
false
false
Q2: there is a arraylist with Employee objects in it. The list contains duplicate Employee objects, Now i need to remove the duplicate objects from the list.how do you do that?
Override equals and hashcode and use equals method to compare two objects.If the class is coming from jar or uneditable use extends and override the hashcode and equals method
Question2.java
import java.util.ArrayList;
import java.util.List;
public class Question2
{
public static void main(String[] args)
{
List<Employee> arrEmp = new ArrayList<Employee>();
Employee objEmp1 = new Employee();
objEmp1.setName("Mugil");
objEmp1.setEmpId(101);
Employee objEmp2 = new Employee();
objEmp2.setName("Mugil");
objEmp2.setEmpId(101);
Employee objEmp3 = new Employee();
objEmp3.setName("mugil");
objEmp3.setEmpId(101);
System.out.println("Both Object are Equal - " + objEmp1.equals(objEmp2));
System.out.println("Both Object are Equal - " + objEmp3.equals(objEmp2));
}
}
Question2.java
class Employee
{
String Name;
int EmpId;
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + EmpId;
result = prime * result + ((Name == null) ? 0 : Name.hashCode());
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Employee other = (Employee) obj;
if (EmpId != other.EmpId)
return false;
if (Name == null) {
if (other.Name != null)
return false;
} else if (!Name.equals(other.Name))
return false;
return true;
}
public String getName() {
return Name;
}
public void setName(String name) {
Name = name;
}
public int getEmpId() {
return EmpId;
}
public void setEmpId(int empId) {
EmpId = empId;
}
}
`
Output
Both Object are Equal - true
Both Object are Equal - false
Q3:What will happen if you call return or System.exit in try or catch block?Will finally block execute?
Scenario 1: Positive Scenario with no System.exit()
package com.mugil.org.qs;
public class Question3
{
public static void main(String[] args)
{
System.out.println(getName());
}
public static String getName()
{
try {
return "Mugil";
} catch (Exception e) {
throw new NullPointerException("return value is null");
}finally {
System.out.println("Finally Block Executed");
}
}
}
Output
Finally Block Executed
Mugil
Scenario 2 :System.exit() in try block before exception
package com.mugil.org.qs;
public class Question3
{
public static void main(String[] args)
{
System.out.println(getName());
}
public static String getName()
{
try {
System.exit(1);
throw new NullPointerException("return value is null");
} catch (Exception e) {
throw new NullPointerException("return value is null");
}finally {
System.out.println("Finally Block Executed");
}
}
}
If the System.exit(1) is used after throw new NullPointerException then it compiler will complain for unreachable code.
Finally will not get executed
Output(Blank Screen)
Scenario 3 :System.exit() in catch block before exception
package com.mugil.org.qs;
public class Question3
{
public static void main(String[] args)
{
System.out.println(getName());
}
public static String getName()
{
try {
throw new NullPointerException("return value is null");
} catch (Exception e) {
System.exit(1);
throw new NullPointerException("return value is null");
}finally {
System.out.println("Finally Block Executed");
}
}
}
Output(Blank Screen)
The only times finally won’t be called are
- If you invoke System.exit();
- If the JVM crashes first;
- If there is an infinite loop
- If the host system dies; e.g. power failure, hardware error
Q3a:What are parameters of System.exit?
- Zero(0) – when execution went fine – Everything Okay
- Positive(1-127) – Something I expected could potentially go wrong went wrong anticipated exception – (bad command-line, can’t find file, could not connect to server)
- Negative(values greater than 128) – Something I didn’t expect at all went wrong (system error – unanticipated exception – externally forced termination e.g. kill -9)
Q4:What is the difference between Iterator and ListIterator
When you loop through list use listiterator since it is faster then iterator. It can traverse in both directions. Iterator can be used over collections whereas list iterator call be used only for list
When you are simple moving through List but you are not modifying the List object foreach is more efficient.In case you want to perform operations on each element of list individually taking out the element in such case use Iterator.
| ListIterator |
Iterator |
| ListIterator to traverse List only |
Iterator is used for traversing List and Set both. |
| ListIterator, we can traverse a List in both the directions (forward and Backward). |
traverse in only forward direction using Iterator |
| We cannot obtain indexes while using Iterator |
We can obtain indexes at any point of time while traversing a list using ListIterator. The methods nextIndex() and previousIndex() are used for this purpose. |
| We can add element at any point of time while traversing a list using ListIterator. |
We cannot add element to collection while traversing it using Iterator, it throws ConcurrentModificationException when you try to do it. |
| By using set(E e) method of ListIterator we can replace the last element returned by next() or previous() methods. |
We cannot replace the existing element value when using Iterator. |
| Methods of ListIterator:
add(E e)
hasNext()
hasPrevious()
next()
nextIndex()
previous()
previousIndex()
remove()
set(E e) |
Methods of Iterator:
hasNext()
next()
remove() |
Q5:What would be the output of Following Program?
package com.mugil.org.qs;
public class Question4
{
public static void main(String[] args)
{
my m = new my(){};
m.myMethod();
System.out.println(m.getClass().getSuperclass());
}
}
abstract class my
{
public void myMethod()
{
System.out.println("Abstract");
}
}
Ans:The reason for this any anonymous class which has the same name as abstract class would be child class of the abstract class
Q6:Why we are unable to add primitives as generic type?
//Allowed
List<Integer> arrAges = new ArrayList<Integer>();
//Not allowed
List<int> arrAges = new ArrayList<int>();
Ans:This is to maintain backwards compatibility with previous JVM runtimes in the sense it could be referred by parent class instance Object
Q7: What would be the Output of following program
package com.mugil.org.qs;
public class Question7
{
public static void main(String[] args) {
System.out.println(getSomeNumber());
}
public static int getSomeNumber()
{
try{
throw new RuntimeException();
}finally{
return 1;
}
}
}
Output
1
Ans: Finally will run at any cause other than system.exit() call.
Q7a: What would be the Output of following program
package com.mugil.org.qs;
public class Question7a
{
public static void main(String[] args)
{
if(isQAAssured())
System.out.println("QA Checked");
else
System.out.println("QA is not Checked");
}
public static boolean isQAAssured()
{
try
{
return true;
}
finally
{
return false;
}
}
}
Output
QA is not Checked
Q7a: What would be the Output of following program
package com.mugil.org.qs;
public class Question8
{
public static void main(String[] args)
{
javaHungry(null);
}
public static void javaHungry(Integer s)
{
System.out.println("Integer");
}
public static void javaHungry(Object s)
{
System.out.println("Object");
}
public static void javaHungry(String s)
{
System.out.println("String");
}
}
Output
Exception in thread "main" java.lang.Error: Unresolved compilation problem:
The method javaHungry(Integer) is ambiguous for the type Question8
Q8:The code wont compile since, To explain the things in details let have a look into the following code
Question8.java
package com.mugil.org.qs;
public class Question8
{
public static void main(String[] args)
{
javaHungry(null);
}
/*public static void javaHungry(Integer s)
{
System.out.println("Integer");
}*/
public static void javaHungry(Object s)
{
System.out.println("Object");
}
public static void javaHungry(String s)
{
System.out.println("String");
}
}
Output
String
The reason the above code worked is java compiler tries to find out the method with most specific input parameters to invoke a method.We know that Object is the parent class of String, so the choice was easy. If more than one member method is both accessible and applicable to a method invocation … The Java programming language uses the rule that the most specific method is chosen.
Now when the same is used in the before code which has String and int.You will get compile time error as The method foo(Object) is ambiguous for the type Test because both String and Integer class have Object as parent class and there is no inheritance. So java compiler doesn’t consider any of them to be more specific, hence the method ambiguous call error.
What would be the output?
package com.mugil.org.qs;
public class Question8
{
public static void main(String[] args)
{
callMe(null);
}
public static void callMe(Exception e) {
System.out.println("Exception");
}
public static void callMe(NullPointerException ne) {
System.out.println("NullPointerException");
}
public static void callMe(Object s)
{
System.out.println("Object");
}
}
Output
NullPointerException
As above explained, here callMe(NullPointerException ne) is the most specific method because it’s inherited from Exception class and hence this code compiles fine and when executed prints “NullPointerException”.
What would be the output?
package com.mugil.org.qs;
public class Question9
{
public static void main(String[] args)
{
System.out.println(methodOfA());
}
public static int methodOfA()
{
return (true?null:1);
}
}
Output
Exception in thread "main" java.lang.NullPointerException
at com.mugil.org.qs.Question9.methodOfA(Question9.java:12)
at com.mugil.org.qs.Question9.main(Question9.java:7)
- Now when you see the above code the first thing you notice is the code might throw compilation error.how a int can return a null.Whenever you return a primitive value from a method then it would be autoboxed to the wrapper type and sent back to calling method
- int is a primitive, null is not a value that it can take on. You could change the method return type to return java.lang.Integer and then you can return null, and existing code that returns int will get autoboxed.
- So the output would be runtimeexception that is NullPointerException
Q9:What would be the output?
package com.mugil.org.qs;
public class Question10
{
public static void main(String[] args)
{
System.out.println("main1");
main ("main2");
}
public static void main(String arg)
{
System.out.println(arg);
}
}
Output
main1
main2
Ans:Overloading static methods are allowed. Overloading is legal, Overriding is illegal since the static methods belong to a class and there could not be method with same name and parameters within the class
Q11:What would be the output?
package com.mugil.org.qs;
public class Question11
{
public static void main(String[] args)
{
try
{
printName();
System.out.println("Inside Try Block");
}
catch (Exception e)
{
System.out.println("Inside Exception Block");
}
finally
{
System.out.println("Inside finally Block");
}
}
public static void printName()
{
throw new Error();
}
}
Output
Exception in thread "main" Inside finally Block
java.lang.Error
at com.mugil.org.qs.Question11.printName(Question11.java:24)
at com.mugil.org.qs.Question11.main(Question11.java:9)
Ans:-Control will go inside finally and Inside finally Block would be printed despite error.
Q11:What would be the output?
package com.mugil.org.qs;
public class Question12
{
public static void main(String[] args)
{
Animal[] arrAnimal = {new Animal(), new Dog(),new Animal()};
for (int i = 0; i < arrAnimal.length; i++)
{
arrAnimal[i].doStuff();
}
}
}
class Animal
{
public static void doStuff()
{
System.out.println("Animal Stuff");
}
}
class Dog extends Animal
{
public static void doStuff()
{
System.out.println("Dog Stuff");
}
}
Output
Animal Stuff
Animal Stuff
Animal Stuff
Ans:-Since the methods are static it belongs to class not objects, the reference types are ignored and the calling type are considered. In our case Animal.
Q12:Why Fail fast are not thread safe where as fail safe are thread safe?
Concurrent Modification: Concurrent Modification in programming is to modify an object concurrently when another task is already running over it. For example, in Java to modify a collection when another thread is iterating over it. Some Iterator implementations may choose to throw ConcurrentModificationException if this behavior is detected.
Iterators in java are used to iterate over the Collection objects.Fail-Fast iterators immediately throw ConcurrentModificationException if there is structural modification of the collection. Structural modification means adding, removing or updating any element from collection while a thread is iterating over that collection. Iterator on ArrayList, HashMap classes are some examples of fail-fast Iterator.Fail-Safe iterators don’t throw any exceptions if a collection is structurally modified while iterating over it. This is because, they operate on the clone of the collection, not on the original collection and that’s why they are called fail-safe iterators. Iterator on CopyOnWriteArrayList, ConcurrentHashMap classes are examples of fail-safe Iterator.
To know whether the collection is structurally modified or not, fail-fast iterators use an internal flag called modCount which is updated each time a collection is modified.Fail-fast iterators checks the modCount flag whenever it gets the next value (i.e. using next() method), and if it finds that the modCount has been modified after this iterator has been created, it throws ConcurrentModificationException.
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
public class FailFastExample {
public static void main(String[] args)
{
Map<String, String> cityCode = new HashMap<String, String>();
cityCode.put("Delhi", "India");
cityCode.put("Moscow", "Russia");
cityCode.put("New York", "USA");
Iterator iterator = cityCode.keySet().iterator();
while (iterator.hasNext()) {
System.out.println(cityCode.get(iterator.next()));
// adding an element to Map
// exception will be thrown on next call
// of next() method.
cityCode.put("Istanbul", "Turkey");
}
}
}
Output
India
Exception in thread "main" java.util.ConcurrentModificationException
at java.util.HashMap$HashIterator.nextNode(HashMap.java:1442)
at java.util.HashMap$KeyIterator.next(HashMap.java:1466)
at FailFastExample.main(FailFastExample.java:18)
Q13:What is Marshalling and Unmarshalling?
To marshall an object is to convert it into a form suitable for serialised storage or transmission; that is, to convert it from its native form within the JVM’s memory, into a form that could be sent down a wire, inserted into a file/database, etc. The specifics will vary depending on the form of marshalling involved; Java’s default serialisation mechanism is one way, but converting the object into an XML or JSON representation are equally valid.
Unmarshalling is just the reverse/other side of this process; taking a representation of the object created by marshalling, and using it to reconstitute an object instance within the JVM.
Q14:What will happen if we directly call run method?
class TestRunnable implements Runnable
{
public static void main(String[] args)
{
TestRunnable nr = new TestRunnable();
Thread t = new Thread(nr);
t.setName("Fred");
t.start();
}
public void run()
{
System.out.println("TestRunnable in " + Thread.currentThread().getName());
}
}
Output if only start is called:
TestRunnable in Fred
Output if only run is called:
TestRunnable in main
Existing thread will stop it’s current execution and it will call the newly created thread for which you called run()
Q14:Why is char[] preferred over String for passwords?
Strings are immutable. That means once you’ve created the String, if another process can dump memory, there’s no way (aside from reflection) you can get rid of the data before garbage collection kicks in.Character arrays (char[]) can be cleared after use by setting each character to zero and Strings not. If someone can somehow see the memory image, they can see a password in plain text if Strings are used, but if char[] is used, after purging data with 0’s, the password is secure.With an array, you can explicitly wipe the data after you’re done with it. You can overwrite the array with anything you like, and the password won’t be present anywhere in the system, even before garbage collection.
Q15:Java is pass-by-value or pass-by-reference?
Java is pass-by-value.Value of reference(address) is passed as value.
public class Question13
{
public static void main(String[] args)
{
Points objPoints = new Points();
Question13 objQuestion13 = new Question13();
objPoints.setPoint(10);
System.out.println(objPoints.getPoint());
objQuestion13.swap(objPoints);
System.out.println(objPoints.getPoint());
objQuestion13.swapValue(objPoints);
System.out.println(objPoints.getPoint());
}
public void swap(Points pobjPoints)
{
Points objPoints = new Points();
objPoints.setPoint(30);
pobjPoints = objPoints;
}
public void swapValue(Points pobjPoints)
{
pobjPoints.setPoint(30);
}
}
class Points
{
Integer point;
public Integer getPoint() {
return point;
}
public void setPoint(Integer point) {
this.point = point;
}
}
Output
10
10
30
- In the above program in the swap method we are passing the reference as value.So inside swap method the reference is assigned to new value and nothing happens outside
- In the swapvalue method again reference is passed as parameter, but we change the value by setting the value inside the location, inside the container using the setter method. so the changes we do inside would be shown up outside
Q16:Why does StringBuffer/StringBuilder not override equals or hashCode?
String Name1=new String("Mugil");
String Name2=new String("Mugil");
Map<String, Integer> hmNames = new HashMap();
hmNames.put(Name1, 30);
hmNames.put(Name1, 48);
for (Map.Entry<String,Integer> entry : hmNames.entrySet())
System.out.println("Key = " + entry.getKey() + ", Value = " + entry.getValue());
Output
Key = Mugil, Value = 48
StringBuilder Name1 = new StringBuilder("Mugil");
StringBuilder Name2 = new StringBuilder("Mugil");
Map<StringBuilder, Integer> hmNames = new HashMap();
hmNames.put(Name1, 30);
hmNames.put(Name1, 25);
for (Map.Entry<StringBuilder,Integer> entry : hmNames.entrySet())
System.out.println("Key = " + entry.getKey() + ", Value = " + entry.getValue());
Output
Key = Mugil, Value = 25
overriding hashCode() for mutable objects, since modifying such an object that is used as a key in a HashMap could cause the stored value to be “lost.”.In other sense if you have overridden the hashcode then the class would become mutable like in first hashmap example where String becomes mutable incontext to hashMap.String are immutable, but when the same is used in hashMap it becomes mutable because strings having Same value despite having different memory locations replace the before string since they have hashcode and equals overridden in their class.
Q17:When do you prefer to use ibatis over hibernate
Hibernate works well for case Create/Update/Delete some complex domain entities.myBatis is great for fetch queries (case 2) where you just want an answer. Run analytic fetch queries (i.e. summation/aggregation queries).Hibernate would attempt to load the entire object graph and you’d need to start tuning queries with LazyLoading tricks to keep it working on a large domain. Conversely if you just want some analytic POJO page, the myBatis implementation of the same query would be trivial.
Q18:What is the difference between singleton scope in spring and singleton pattern?
One is scope of bean in spring container and another is design pattern, single object per jvm instance.
Q19:Why does Map interface not extend the Collection interface in the Java Collections Framework?
One of the reason is other than map, all the interfaces designed to store a single element. But map is storing the elements in the key value pair.So methods in Collection interface are incompatible for Map interface.Same argument goes for addAll(), remove(), removeAll() methods. So the main reason is the difference in the way data is stored in Map and Collections.
Q20:How to create a ArrayList of fixed size in java
Note the question again.The question is wrong.For arrayList we can only set the Capacity not Size.
Capacity is how many elements the list can potentially accommodate without reallocating its internal structures.When you call new ArrayList(10), you are setting the list’s initial capacity, not its size.Size is the number of elements in the list.So the question supposed to be how will you allocate arrayList with some number of capacity.
List<Integer> arr = new ArrayList<Integer>(10);
System.out.println(arr);
System.out.println(arr.size());
Output
[]
0
So from above code though the memory space for the arrayList has been allocated the size of the array is still 0.
Now I want to allocated ArrayList with Size 10 with initial values being 0 in that.
public static void main(String[] args)
{
ArrayList<Integer> arr = new ArrayList<Integer>(Collections.nCopies(10, 0));
System.out.println(arr);
System.out.println(arr.get(0));
}
Output
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
0
Q21:Has anyone used ArrayBlockingQueue? How does it work ?
The ArrayBlockingQueue class implements the BlockingQueue interface. ArrayBlockingQueue is a bounded, blocking queue that stores the elements internally in an array. That it is bounded means that it cannot store unlimited amounts of elements. There is an upper bound on the number of elements it can store at the same time. You set the upper bound at instantiation time, and after that it cannot be changed.
BlockingQueue<String> queue = new ArrayBlockingQueue<String>(1024);
queue.put("1");
String string = queue.take();
Q21:What is the significance of the attribute delete orphan in hibernate
DELETE_ORPHAN means if an entity is removed from a related one-to-many collection, then not only disassociate it from the current entity, but delete it.Lets take a Employee and Address Model.If you do a Cascade Delete in the Employee then the Employee rows would be removed from the Employee table and the association between the Address and the Employee is removed. The Row in Address table still exist and its a orphan record not referred. Now when you do delete orphan also this row in the address table would also be deleted.
de-associating the parent and child relation and then immediately delete orphan records from db.
Q22:What is difference between pojo and javabean?
Please Refer Answer
Q23: Difference between comparator and comparable?
Please Refer Here
Q24: What is coercion polymorphism in java
For example, you divide an integer by another integer or a floating-point value by another floating-point value. If one operand is an integer and the other operand is a floating-point value, the compiler coerces (implicitly converts) the integer to a floating-point value to prevent a type error. (There is no division operation that supports an integer operand and a floating-point operand.) Another example is passing a subclass object reference to a method’s superclass parameter. The compiler coerces the subclass type to the superclass type to restrict operations to those of the superclass.
Q25: What is double dispatching
please refer here
Q26: How does cocurrentmodification exception occur while modifying array list. To be precise based on which indicator
When we iterate through the same list and when we try to modify the same list … Then we get the concurrent modification exception …
Fail fast iterator is used for iteration so we get that error.There is an indicator called modcount which is checked inbetween every operation to make sure whether List is modified or not.
Q27: How will you copy object attributes from one object to another or how to create a object which has replica of all attributes from another object ?
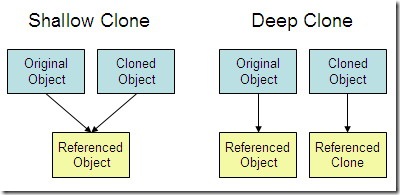
Cloning is a process of creating an exact copy of an existing object in the memory. In java, clone() method of java.lang.Object class is used for cloning process. This method creates an exact copy of an object on which it is called through field-by-field assignment and returns the reference of that object. Not all the objects in java are eligible for cloning process. The objects which implement Cloneable interface are only eligible for cloning process. Cloneable interface is a marker interface which is used to provide the marker to cloning process
Shallow copy
The shallow copy of an object will have exact copy of all the fields of original object. If original object has any references to other objects as fields, then only references of those objects are copied into clone object, copy of those objects are not created. That means any changes made to those objects through clone object will be reflected in original object or vice-versa. Shallow copy is not 100% disjoint from original object. Shallow copy is not 100% independent of original object.
Deep Copy
Deep copy of an object will have exact copy of all the fields of original object just like shallow copy. But in additional, if original object has any references to other objects as fields, then copy of those objects are also created by calling clone() method on them. That means clone object and original object will be 100% disjoint. They will be 100% independent of each other. Any changes made to clone object will not be reflected in original object or vice-versa.
clone is tricky to implement correctly.It’s better to use Defensive copying, copy constructors or static factory methods.
Refer Here
Q28: While doing hashing we use to have prime numbers to perform modulo operation?even when u generate equals and hashcode in eclipse for ur class you would get 31 as divisor, culd someone explain this?
What is Prime Number
A number that is divisible only by itself and 1.Primes are unique numbers. They are unique in that, the product of a prime with any other number has the best chance of being unique due to the fact that a prime is used to compose it. This property is used in hashing functions.Given a string “Samuel”, you can generate a unique hash by multiply each of the constituent digits or letters with a prime number and adding them up. This is why primes are used.
Now why is 31 used?
Using a prime of 31 gives a better distribution to the keys, and lesser no of collisions. If you take over 50,000 English words (formed as the union of the word lists provided in two variants of Unix), using the constants 31, 33, 37, 39, and 41 will produce less than 7 collisions in each case.Using P(31), as it’s the cheapest to calculate (because 31 is the difference of two powers of two). P(33) is similarly cheap to calculate, but it’s performance is marginally worse, and 33 is composite(3*11=33)
Q29:You are thrown with a chained exception, now you need to find the root cause for the exception, which method will you use to get the actual cause for the exception?
Throwable getCause(Throwable e) {
Throwable cause = null;
Throwable result = e;
while(null != (cause = result.getCause()) && (result != cause) ) {
result = cause;
}
return result;
}
Same using Recursion
public static Throwable getRootCause(Throwable throwable) {
if (throwable.getCause() != null)
return getRootCause(throwable.getCause());
return throwable;
}
Using ApacheUtils
Throwable getRootCause(Throwable throwable)
String getRootCauseMessage(Throwable th)