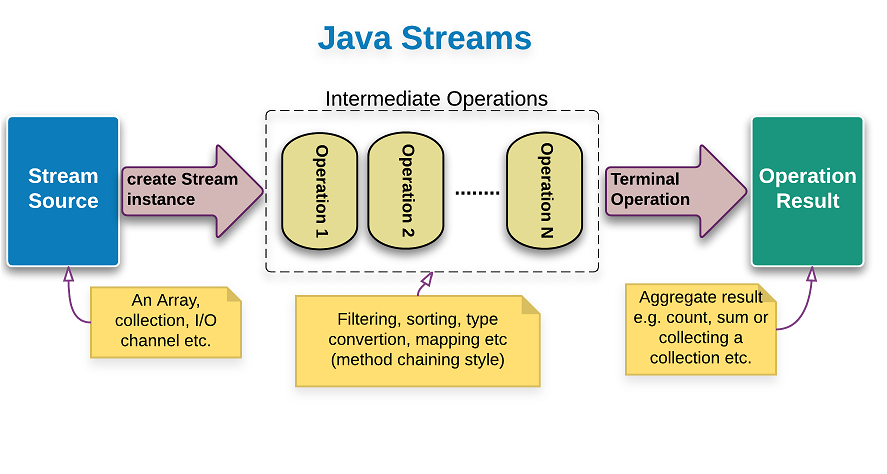
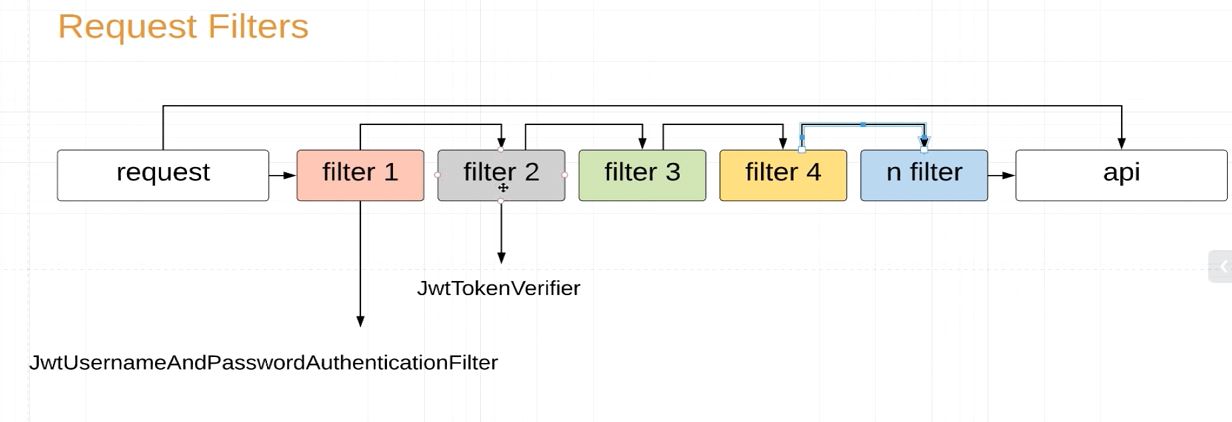
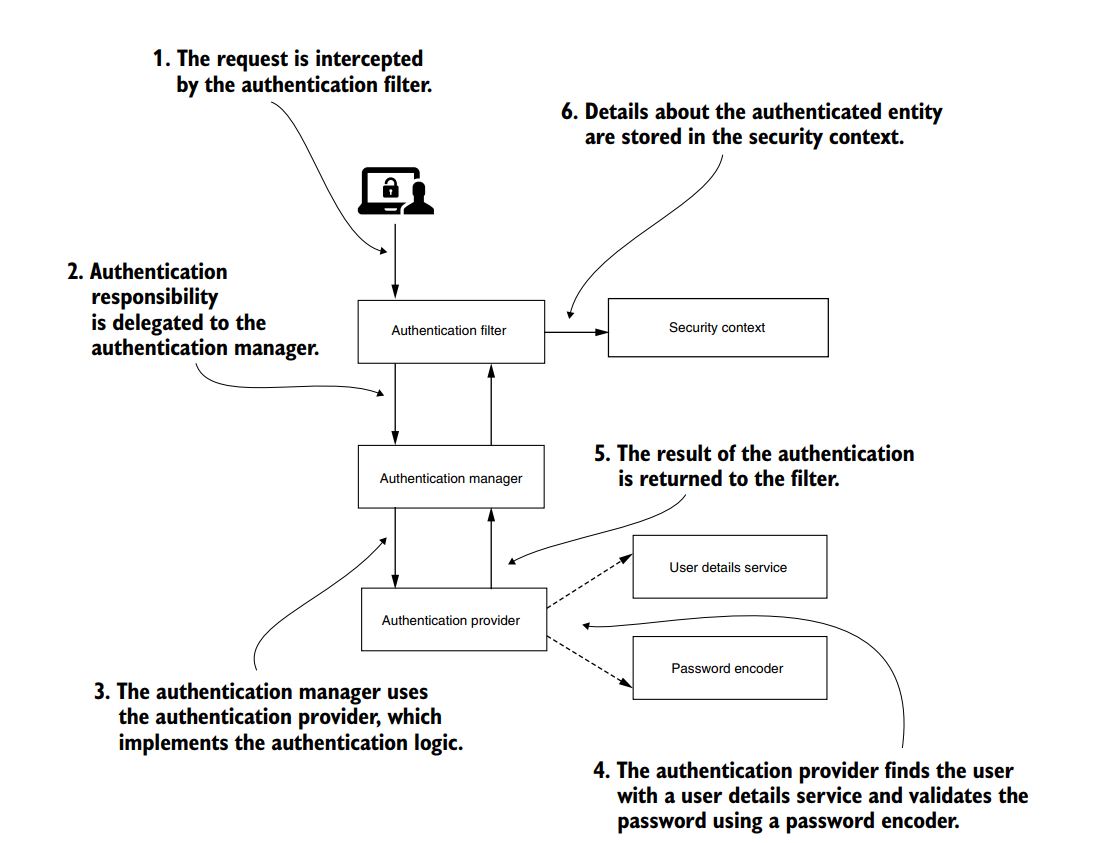
We have a Employee Object with following fields – empId,salary,empAge,totalExp,empName,location,pincode. Now we are going to do following operations in the List containing Employee Object.
import java.util.*;
import java.util.function.Predicate;
import java.util.stream.Collectors;
public class MatchEgs {
public static void main(String[] args) {
Employee objEmp1 = new Employee(101, "Mugil", 30, "Chennai", "600018", 5, 5000);
Employee objEmp2 = new Employee(102, "Mani", 33, "Chennai", "600028", 4, 6000);
Employee objEmp3 = new Employee(103, "Madhu", 32, "Chennai", "600054", 6, 10000);
Employee objEmp4 = new Employee(104, "Vinu", 29, "Bangalore", "500234", 5, 15000);
Employee objEmp5 = new Employee(105, "Srini", 40, "Delhi", "622142", 10, 7000);
Employee objEmp6 = new Employee(106, "Dimple", 35, "Delhi", "622142", 5, 8000);
List<Employee> arrEmployee = Arrays.asList(objEmp1, objEmp2, objEmp3, objEmp4, objEmp5, objEmp6);
}
}
Check if people match the criteria by passing predicate to anyMatch, noneMatch and allMatch
Predicate<Employee> empAgeGreaterThan35 = employee -> employee.getEmpAge() > 35;
Predicate<Employee> empAgeGreaterThan30 = employee -> employee.getEmpAge() > 30;
Predicate<Employee> empStayingInDelhi = employee -> employee.getLocation().equals("Delhi");
//Check if Some Employee Age is Greater 30
System.out.println(arrEmployee.stream().anyMatch(empAgeGreaterThan35));
//Check if all Employee Age is above 30
System.out.println(arrEmployee.stream().allMatch(empAgeGreaterThan30));
//Check if any Employee Location in Delhi
System.out.println(arrEmployee.stream().noneMatch(empStayingInDelhi));
Sort Employee by Name passing Comparator using Sorted and reversed. Sort based on more than
one field using thenComparing
Comparator<Employee> sortByName = Comparator.comparing(Employee::getEmpName);
List<Employee> arrSortedByName = arrEmployee.stream()
.sorted(sortByName)
.collect(Collectors.toList());
System.out.println("----------------Sorted By Name----------------");
arrSortedByName.forEach(employee -> System.out.println(employee));
Comparator<Employee> sortByNameReversed = Comparator.comparing(Employee::getEmpName).reversed();
List<Employee> arrSortedByNameRev = arrEmployee.stream()
.sorted(sortByNameReversed)
.collect(Collectors.toList());
System.out.println("----------------Sorted By Name Reversed----------------");
arrSortedByNameRev.forEach(employee -> System.out.println(employee));
Comparator<Employee> sortByNameanAge = Comparator.comparing(Employee::getEmpName).thenComparing(Employee::getEmpAge);
List<Employee> arrSortedByNameAge = arrEmployee.stream()
.sorted(sortByNameanAge)
.collect(Collectors.toList());
System.out.println("----------------Sorted By Name and Age----------------");
arrSortedByNameAge.forEach(employee -> System.out.println(employee));
Limit and Skip records using limit and skip
System.out.println("----------------Limit Records to 3 ----------------");
List<Employee> arrEmp3 = arrEmployee.stream()
.limit(3)
.collect(Collectors.toList());
arrEmp3.forEach(employee -> System.out.println(employee));
System.out.println("----------------Skip First 3 Records ----------------");
List<Employee> arrEmp4 = arrEmployee.stream()
.skip(3)
.collect(Collectors.toList());
arrEmp4.forEach(employee -> System.out.println(employee));
doWhile when condition is true using takeWhile and vice-versa(Until condition is met) using dropWhile
System.out.println("----------------Print Records until Chennai - Keeps printing until condition is True----------------");
List<Employee> arrEmp5 = arrEmployee.stream()
.takeWhile(employee -> employee.getLocation().equals("Chennai"))
.collect(Collectors.toList());
arrEmp5.forEach(employee -> System.out.println(employee));
System.out.println("----------------Print Records until Chennai - Stops printing when condition is Met ----------------");
List<Employee> arrEmp6 = arrEmployee.stream()
.dropWhile(employee -> employee.getLocation().equals("Bangalore"))
.collect(Collectors.toList());
arrEmp5.forEach(employee -> System.out.println(employee));
Get Minimum and Maximum age of employee using min and max. The List should be sorted first using comparator. Similarly get Employee with max experience in a particular location using predicate, comparator and max.
System.out.println("----------------Record with Min and Max Value ----------------");
Comparator<Employee> sortByAge = Comparator.comparing(Employee::getEmpAge);
List<Employee> arrEmp7 = arrEmployee.stream()
.min(sortByAge)
.stream()
.collect(Collectors.toList());
List<Employee> arrEmp8 = arrEmployee.stream()
.max(sortByAge)
.stream()
.collect(Collectors.toList());
arrEmp7.forEach(employee -> System.out.println(employee));
arrEmp8.forEach(employee -> System.out.println(employee));
System.out.println("----------------Get Employee with Max Exp in Chennai ----------------");
Predicate<Employee> filterEmpInChennai = employee -> employee.getLocation().equals("Chennai");
Comparator<Employee> sortByExp = Comparator.comparing(Employee::getTotalExp);
List<Employee> arrEmp11 = arrEmployee.stream()
.filter(filterEmpInChennai)
.max(sortByExp)
.stream()
.collect(Collectors.toList());
arrEmp11.forEach(employee -> System.out.println(employee));
FindFirst Employee who matches criteria and FindAny who matches criteria. Both takes predicate as input.
System.out.println("----------------Find First ----------------");
Predicate<Employee> empStayingInChennai = employee -> employee.getLocation().equals("Chennai");
List<Employee> arrEmp9 = arrEmployee.stream()
.filter(empStayingInChennai)
.findFirst()
.stream()
.collect(Collectors.toList());
arrEmp9.forEach(employee -> System.out.println(employee));
System.out.println("----------------Find Any ----------------");
List<Employee> arrEmp10 = arrEmployee.stream()
.filter(empAgeGreaterThan30)
.findAny()
.stream()
.collect(Collectors.toList());
arrEmp10.forEach(employee -> System.out.println(employee));
Get the Sum of salary of Employees in Location(Chennai) using sum
System.out.println("----------------Sum - Get Sum of Salary in Chennai ----------------");
//Method 1
Integer empTotalSalaryInChennai1 = arrEmployee.stream()
.filter(empStayingInChennai)
.map(employee -> employee.getSalary())
.collect(Collectors.toList())
.stream()
.reduce(0, Integer::sum);
System.out.println("Sum of Empl Salary - Chennai " + empTotalSalaryInChennai1);
//Method 2
Integer empTotalSalaryInChennai2 = arrEmployee.stream()
.filter(empStayingInChennai)
.mapToInt(Employee::getSalary).sum();
System.out.println("Sum of Empl Salary - Chennai " + empTotalSalaryInChennai2);
//Method 3
Integer empTotalSalaryInChennai3 = arrEmployee.stream()
.filter(empStayingInChennai)
.map(employee -> employee.getSalary())
.collect(Collectors.summingInt(Integer::intValue));
System.out.println("Sum of Empl Salary - Chennai " + empTotalSalaryInChennai3);
Get Average salary of employee in location using average
System.out.println("----------------Average - Get Average of Salary in Chennai ----------------");
OptionalDouble empAvgSalaryInChennai = arrEmployee.stream()
.filter(empStayingInChennai)
.mapToInt(Employee::getSalary)
.average();
System.out.println("Average Salary of Employee - Chennai " + empAvgSalaryInChennai);
Get List of Employees in a location using groupingBy. The Return type is hashmap with location as key and List of employees in value
System.out.println("----------------Group By - Get Employees grouped by Location ----------------");
Map<String, List<Employee>> hmEmp13 = arrEmployee.stream()
.collect(Collectors.groupingBy(Employee::getLocation));
hmEmp13.forEach((s, employees) -> {
System.out.println("Employees from "+ s);
employees.forEach(employee -> System.out.println(employee));
});
Get Employee grouped by Location and getting Maximum Salary groupingBy and maxBy
System.out.println("----------------Group By - Get Employees with Max Salary in Location ----------------");
Comparator<Employee> cmprSalary = Comparator.comparing(Employee::getSalary);
Map<String, Optional<Employee>> hmEmp14 = arrEmployee.stream()
.collect(Collectors.groupingBy(Employee::getLocation, Collectors.maxBy(cmprSalary)));
hmEmp14.forEach((s, employee) -> {
System.out.print("Employee Location is "+ s + " and salary is ");
employee.ifPresent(emp -> System.out.println(emp.getSalary()));
});
Get Employee Name using mapping grouped by Location using groupingBy
System.out.println("---------------- Employee at Location - Using Collectors.mapping ----------------");
Map<String, List<String>> hmEmp16 = arrEmployee.stream()
.collect(Collectors.groupingBy(Employee::getLocation, Collectors.mapping(Employee::getEmpName, Collectors.toList())));
hmEmp16.forEach((s, employee) -> {
System.out.println("Employee Name is " + employee + " and Location is "+ s );
});
Output
true
false
false
----------------Sorted By Name----------------
Employee{empId=106, empName='Dimple', empAge=35, totalExp=5, location='Delhi', pincode='622142', salary=8000}
Employee{empId=103, empName='Madhu', empAge=32, totalExp=6, location='Chennai', pincode='600054', salary=10000}
Employee{empId=102, empName='Mani', empAge=33, totalExp=4, location='Chennai', pincode='600028', salary=6000}
Employee{empId=101, empName='Mugil', empAge=30, totalExp=5, location='Chennai', pincode='600018', salary=5000}
Employee{empId=105, empName='Srini', empAge=40, totalExp=10, location='Delhi', pincode='622142', salary=7000}
Employee{empId=104, empName='Vinu', empAge=29, totalExp=5, location='Bangalore', pincode='500234', salary=15000}
----------------Sorted By Name Reversed----------------
Employee{empId=104, empName='Vinu', empAge=29, totalExp=5, location='Bangalore', pincode='500234', salary=15000}
Employee{empId=105, empName='Srini', empAge=40, totalExp=10, location='Delhi', pincode='622142', salary=7000}
Employee{empId=101, empName='Mugil', empAge=30, totalExp=5, location='Chennai', pincode='600018', salary=5000}
Employee{empId=102, empName='Mani', empAge=33, totalExp=4, location='Chennai', pincode='600028', salary=6000}
Employee{empId=103, empName='Madhu', empAge=32, totalExp=6, location='Chennai', pincode='600054', salary=10000}
Employee{empId=106, empName='Dimple', empAge=35, totalExp=5, location='Delhi', pincode='622142', salary=8000}
----------------Sorted By Name and Age----------------
Employee{empId=106, empName='Dimple', empAge=35, totalExp=5, location='Delhi', pincode='622142', salary=8000}
Employee{empId=103, empName='Madhu', empAge=32, totalExp=6, location='Chennai', pincode='600054', salary=10000}
Employee{empId=102, empName='Mani', empAge=33, totalExp=4, location='Chennai', pincode='600028', salary=6000}
Employee{empId=101, empName='Mugil', empAge=30, totalExp=5, location='Chennai', pincode='600018', salary=5000}
Employee{empId=105, empName='Srini', empAge=40, totalExp=10, location='Delhi', pincode='622142', salary=7000}
Employee{empId=104, empName='Vinu', empAge=29, totalExp=5, location='Bangalore', pincode='500234', salary=15000}
----------------Limit Records to 3 ----------------
Employee{empId=101, empName='Mugil', empAge=30, totalExp=5, location='Chennai', pincode='600018', salary=5000}
Employee{empId=102, empName='Mani', empAge=33, totalExp=4, location='Chennai', pincode='600028', salary=6000}
Employee{empId=103, empName='Madhu', empAge=32, totalExp=6, location='Chennai', pincode='600054', salary=10000}
----------------Skip First 3 Records ----------------
Employee{empId=104, empName='Vinu', empAge=29, totalExp=5, location='Bangalore', pincode='500234', salary=15000}
Employee{empId=105, empName='Srini', empAge=40, totalExp=10, location='Delhi', pincode='622142', salary=7000}
Employee{empId=106, empName='Dimple', empAge=35, totalExp=5, location='Delhi', pincode='622142', salary=8000}
----------------Print Records until Chennai - Keeps printing until condition is True----------------
Employee{empId=101, empName='Mugil', empAge=30, totalExp=5, location='Chennai', pincode='600018', salary=5000}
Employee{empId=102, empName='Mani', empAge=33, totalExp=4, location='Chennai', pincode='600028', salary=6000}
Employee{empId=103, empName='Madhu', empAge=32, totalExp=6, location='Chennai', pincode='600054', salary=10000}
----------------Print Records until Chennai - Stops printing when condition is Met ----------------
Employee{empId=101, empName='Mugil', empAge=30, totalExp=5, location='Chennai', pincode='600018', salary=5000}
Employee{empId=102, empName='Mani', empAge=33, totalExp=4, location='Chennai', pincode='600028', salary=6000}
Employee{empId=103, empName='Madhu', empAge=32, totalExp=6, location='Chennai', pincode='600054', salary=10000}
----------------Record with Min and Max Value ----------------
Employee{empId=104, empName='Vinu', empAge=29, totalExp=5, location='Bangalore', pincode='500234', salary=15000}
Employee{empId=105, empName='Srini', empAge=40, totalExp=10, location='Delhi', pincode='622142', salary=7000}
----------------Get Employee with Max Exp in Chennai ----------------
Employee{empId=103, empName='Madhu', empAge=32, totalExp=6, location='Chennai', pincode='600054', salary=10000}
----------------Find First ----------------
Employee{empId=101, empName='Mugil', empAge=30, totalExp=5, location='Chennai', pincode='600018', salary=5000}
----------------Find Any ----------------
Employee{empId=102, empName='Mani', empAge=33, totalExp=4, location='Chennai', pincode='600028', salary=6000}
----------------Sum - Get Sum of Salary in Chennai ----------------
Sum of Empl Salary - Chennai 21000
Sum of Empl Salary - Chennai 21000
Sum of Empl Salary - Chennai 21000
----------------Average - Get Average of Salary in Chennai ----------------
Average Salary of Employee - Chennai OptionalDouble[7000.0]
----------------Group By - Get Employees grouped by Location ----------------
Employees from Delhi
Employee{empId=105, empName='Srini', empAge=40, totalExp=10, location='Delhi', pincode='622142', salary=7000}
Employee{empId=106, empName='Dimple', empAge=35, totalExp=5, location='Delhi', pincode='622142', salary=8000}
Employees from Chennai
Employee{empId=101, empName='Mugil', empAge=30, totalExp=5, location='Chennai', pincode='600018', salary=5000}
Employee{empId=102, empName='Mani', empAge=33, totalExp=4, location='Chennai', pincode='600028', salary=6000}
Employee{empId=103, empName='Madhu', empAge=32, totalExp=6, location='Chennai', pincode='600054', salary=10000}
Employees from Bangalore
Employee{empId=104, empName='Vinu', empAge=29, totalExp=5, location='Bangalore', pincode='500234', salary=15000}
----------------Group By - Get Employees with Max Salary in Location ----------------
Employee Location is Delhi and salary is 8000
Employee Location is Chennai and salary is 10000
Employee Location is Bangalore and salary is 15000
---------------- Employee at Location - Get Employee Object grouped by Location ----------------
Employee Location is Delhi
Srini
Dimple
Employee Location is Chennai
Mugil
Mani
Madhu
Employee Location is Bangalore
Vinu
---------------- Employee at Location - Using Collectors.mapping ----------------
Employee Name is [Srini, Dimple] and Location is Delhi
Employee Name is [Mugil, Mani, Madhu] and Location is Chennai
Employee Name is [Vinu] and Location is Bangalore