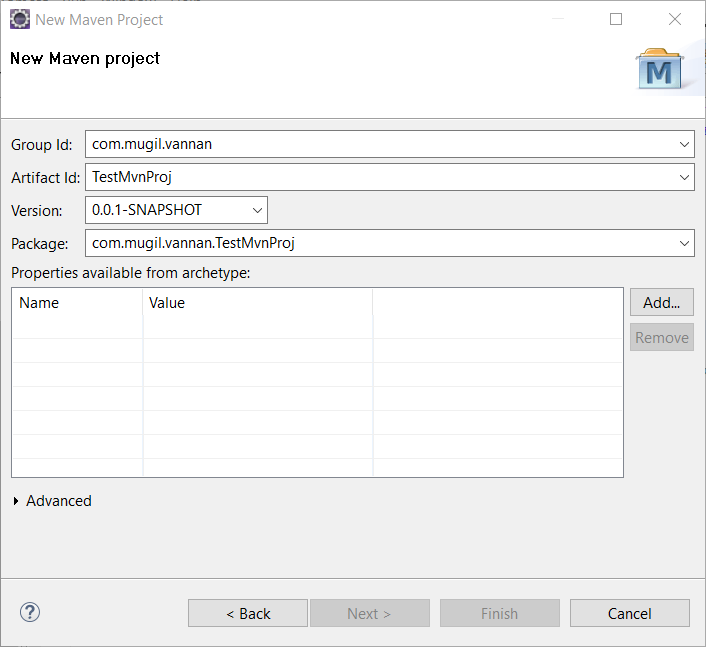
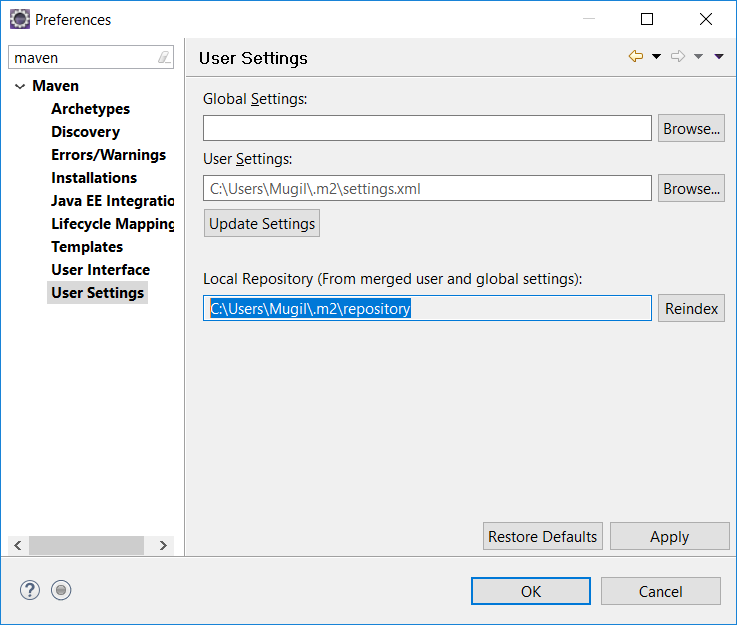
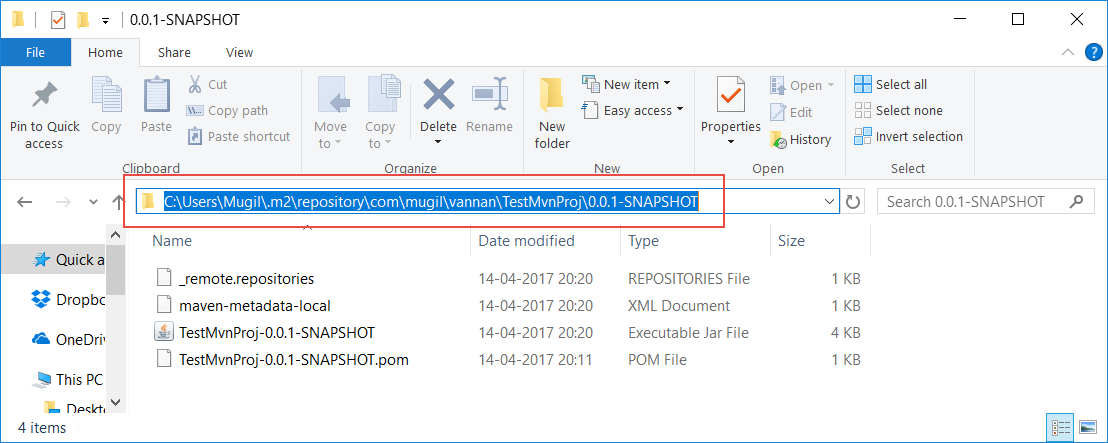
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
</dependencies>
Specifying Version
<!--Version should be 3.8.1-->
<version>3.8.1</version>
<!--Version should less than or up to 3.8-->
<version>[,3.8]</version>
<!--Version should less than 3.8-->
<version>[,3.8)</version>
<!--Version should be between 3.1 to 3.8-->
<!--If 3.8 is available it picks those-->
<version>[3.1,3.8]</version>
Specifying Scope
<!--Jar file would be available to JUnit Test Folder-->
<scope>test</scope>
<!--available as Part of Web Server i.e tools.jar-->
<scope>provided</scope>
<!--Jar File available only during runtime-->
<!--Use of Interface at Compile Time and actual class at runtime-->
<scope>runtime</scope>
<!--Use of Interface at Compile Time and actual class at runtime-->
<scope>runtime</scope>
Defines the Maven Plugin with which the compilation has to be carried out
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.6.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
Effective POM
Tells the Details of Super POM.xml Lists default configuration.
.
.
<build>
<sourceDirectory>D:\java\TestMvnProj2\src\main\java</sourceDirectory>
<testSourceDirectory>D:\java\TestMvnProj2\src\test\java</testSourceDirectory>
<outputDirectory>D:\java\TestMvnProj2\target\classes</outputDirectory>
</build>
.
.
The above XML code specify the details of sourceDirectory, outputDirectory
You can also see list of plugins called at different phases of maven life cycle.
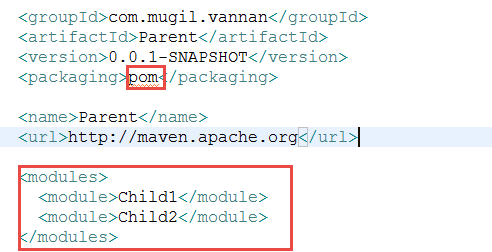
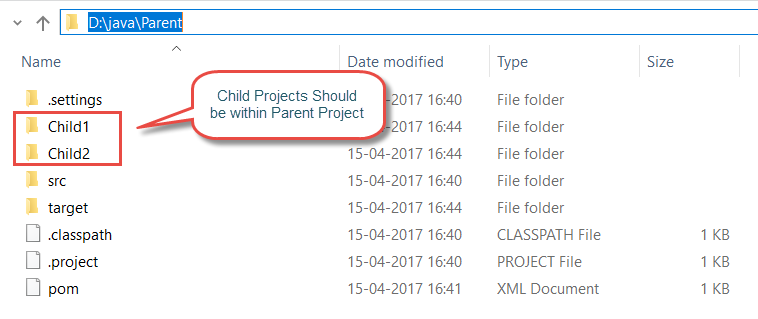
Parent POM
List of Child Projects are added into modules as separate module.
.
.
<packaging>pom</packaging>
<modules>
<module>Service</module>
<module>Controller</module>
<module>Model</module>
</modules>
.
.